
008.Binder 驱动情景分析之服务注册过程
本文系统源码版本:
- AOSP 分支:android-10.0.0_r41
- Kernel 分支:android-goldfish-4.14-gchips
本文依托于Binder 程序示例之 C 语言篇中介绍的应用层示例程序来对驱动的实现做情景化分析。
上文说到,ServiceManager 进入循环,开始读数据后,就进入休眠状态,直到有其他进程写入数据并唤醒他为止。接下来我们就来看看 ServiceManager 是怎么被 Server 端唤醒的。
1. Server 主函数
int main(int argc, char **argv)
{
struct binder_state *bs;
uint32_t svcmgr = BINDER_SERVICE_MANAGER;
uint32_t handle;
int ret;
//Binder 初始化
bs = binder_open("/dev/binder",
*1024);
if (!bs) {
fprintf(stderr, "failed to open binder driver\n");
return -1;
}
//svcmgr 的值是 0,表示发送信息给 servicemanager
//注册服务
ret = svcmgr_publish(bs, svcmgr, "hello", hello_service_handler);
if (ret) {
fprintf(stderr, "failed to publish hello service\n");
return -1;
}
//进入 loop, 等待 client 请求服务
binder_loop(bs, test_server_handler);
return 0;
}Server 端发起服务注册请求的流程如下图所示:
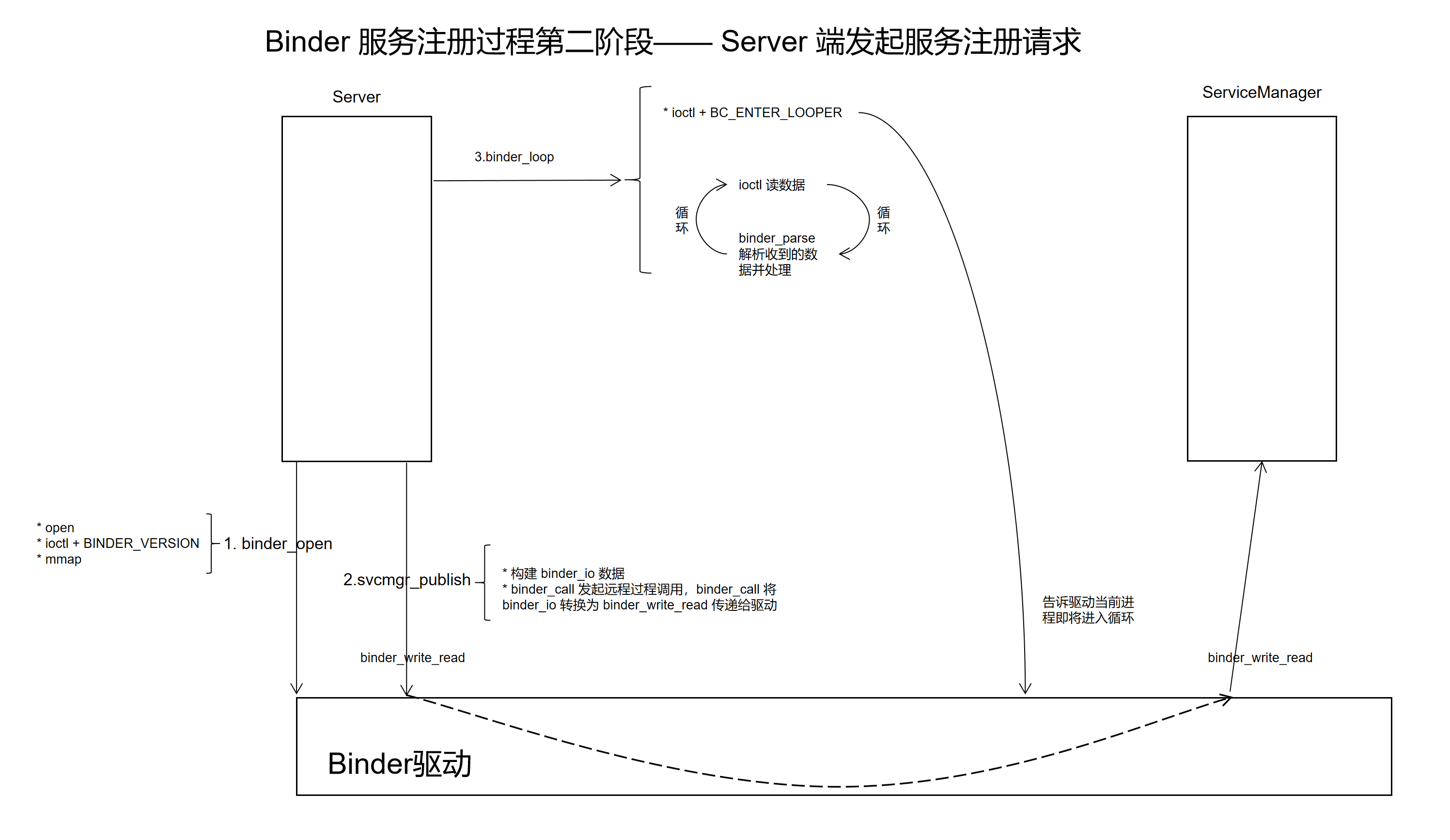
2. binder_open
binder_open 的调用流程与 ServiceManager 一致,这里不再重复,总结一下就是:binder_open 主要是初始化了一个 binder_proc 结构体,并插入到全局的链表 procs 中了。
3. svcmgr_publish 实现分析
svcmgr_publish 用于发布一个服务,其具体实现如下:
int svcmgr_publish(struct binder_state *bs, uint32_t target, const char *name, void *ptr)
{
int status;
unsigned iodata[512/4];
struct binder_io msg, reply;
bio_init(&msg, iodata, sizeof(iodata), 4);
bio_put_uint32(&msg, 0); // strict mode header
bio_put_uint32(&msg, 0);
//SVC_MGR_NAME 值为 "android.os.IServiceManager"
bio_put_string16_x(&msg, SVC_MGR_NAME);
//name 的值是 hello
bio_put_string16_x(&msg, name);
//ptr 是一个函数指针指向 hello_service_handler
bio_put_obj(&msg, ptr);
bio_put_uint32(&msg, 0);
bio_put_uint32(&msg, 0);
//通过 binder_call 发起远程函数调用
if (binder_call(bs, &msg, &reply, target, SVC_MGR_ADD_SERVICE)) {
//fprintf(stderr, "svcmgr_public 远程调用失败\n");
return -1;
}
//解析返回值
status = bio_get_uint32(&reply); //调用成功返回0
//远程调用结束,通知驱动清理内存
binder_done(bs, &msg, &reply);
return status;
}svcmgr_publish 工作流程如下:
- 通过 binder_io 构造需要发送的数据 msg
- 通过 binder_call 发起远程调用
- 解析回复的数据,通过 binder_done 函数通知驱动通信完成,清理内存
接下来我们深入到内核一一分析这三个阶段:
3.1 通过 binder_io 构造需要发送的数据 msg
binder_io 可以理解为一个数据集合,数据发送端将数据按照一定的顺序写入集合,数据接受端按照相同的顺序读取数据。
svcmgr_publish 中使用如下代码构建了一个 binder_io 结构体:
unsigned iodata[512/4];
struct binder_io msg, reply;
bio_init(&msg, iodata, sizeof(iodata), 4);
bio_put_uint32(&msg, 0); // strict mode header
bio_put_uint32(&msg, 0);
//SVC_MGR_NAME 值为 "android.os.IServiceManager"
bio_put_string16_x(&msg, SVC_MGR_NAME);
//name 的值是 hello
bio_put_string16_x(&msg, name);
//ptr 是一个函数指针指向 hello_service_handler
bio_put_obj(&msg, ptr);
bio_put_uint32(&msg, 0);
bio_put_uint32(&msg, 0);接下来我们看看 binder_io 的具体定义:
struct binder_io
{
char *data; /* pointer to read/write from */
binder_size_t *offs; /* array of offsets */
size_t data_avail; /* bytes available in data buffer */
size_t offs_avail; /* entries available in offsets array */
char *data0; /* start of data buffer */
binder_size_t *offs0; /* start of offsets buffer */
uint32_t flags;
uint32_t unused;
};binder_io 的初始化过程:
//初始化过程
unsigned iodata[512/4];
struct binder_io msg;
//初始化 binder_io
bio_init(&msg, iodata, sizeof(iodata), 4);
void bio_init(struct binder_io *bio, void *data,
size_t maxdata, size_t maxoffs)
{
size_t n = maxoffs * sizeof(size_t);
//溢出处理
if (n > maxdata) {
bio->flags = BIO_F_OVERFLOW;
bio->data_avail = 0;
bio->offs_avail = 0;
return;
}
//将 bio 一分为二
bio->data = bio->data0 = (char *) data + n;
bio->offs = bio->offs0 = data;
bio->data_avail = maxdata - n;
bio->offs_avail = maxoffs;
bio->flags = 0;
}从 binder_io 的定义和初始化过程中可以看出,binder_io 用于管理一块内存,同时将内存分为了两部分管理:
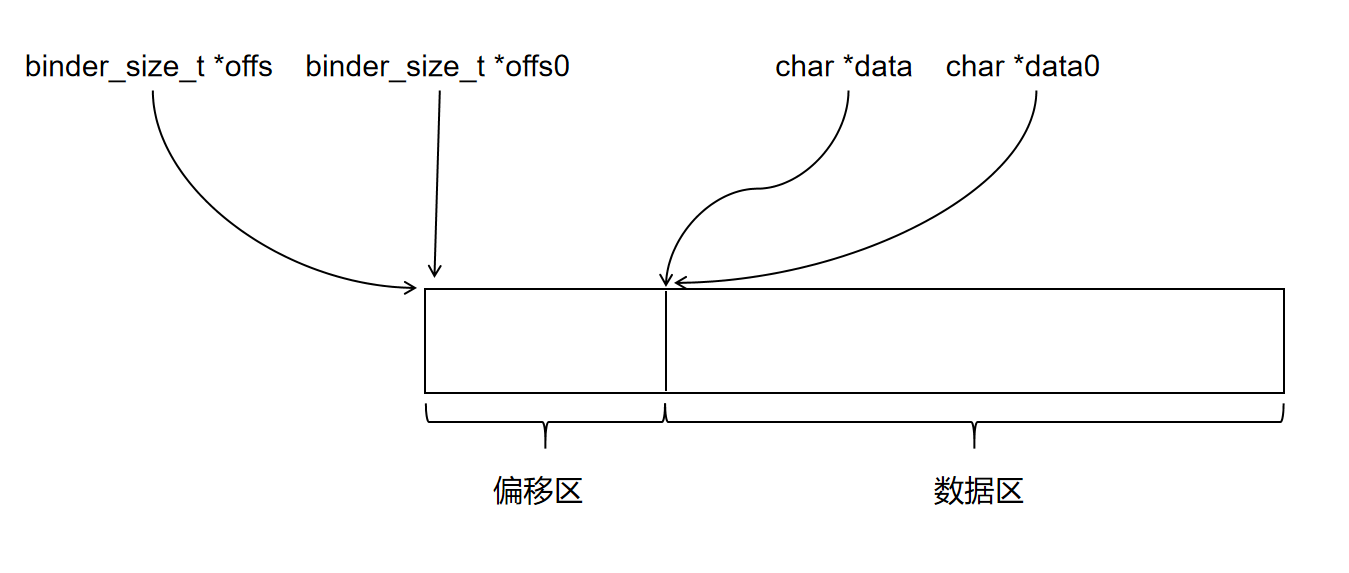
为方便叙述,本文称这两个区为偏移区和数据区。
maxdata 是这块内存总的字节数,偏移区的大小为 n 字节,其中 n = maxoffs * sizeof(size_t),数据区的大小为 maxdata - n
两块内存如何使用?
接下来我们看看如何将一个 unit32_t 数据存入 binder_io:
void bio_put_uint32(struct binder_io *bio, uint32_t n)
{
//分配内存
uint32_t *ptr = bio_alloc(bio, sizeof(n));
if (ptr)
*ptr = n;
}
//在 binder_io 的第二部分分配 size 大小的内存
static void *bio_alloc(struct binder_io *bio, size_t size)
{
//size 最终等于 4,8,12,16,20 ......
//size 的值比原始的值大
size = (size + 3) & (~3);
//溢出操作
if (size > bio->data_avail) {
bio->flags |= BIO_F_OVERFLOW;
return NULL;
} else {
//分配位置
void *ptr = bio->data;
bio->data += size;
bio->data_avail -= size;
return ptr;
}
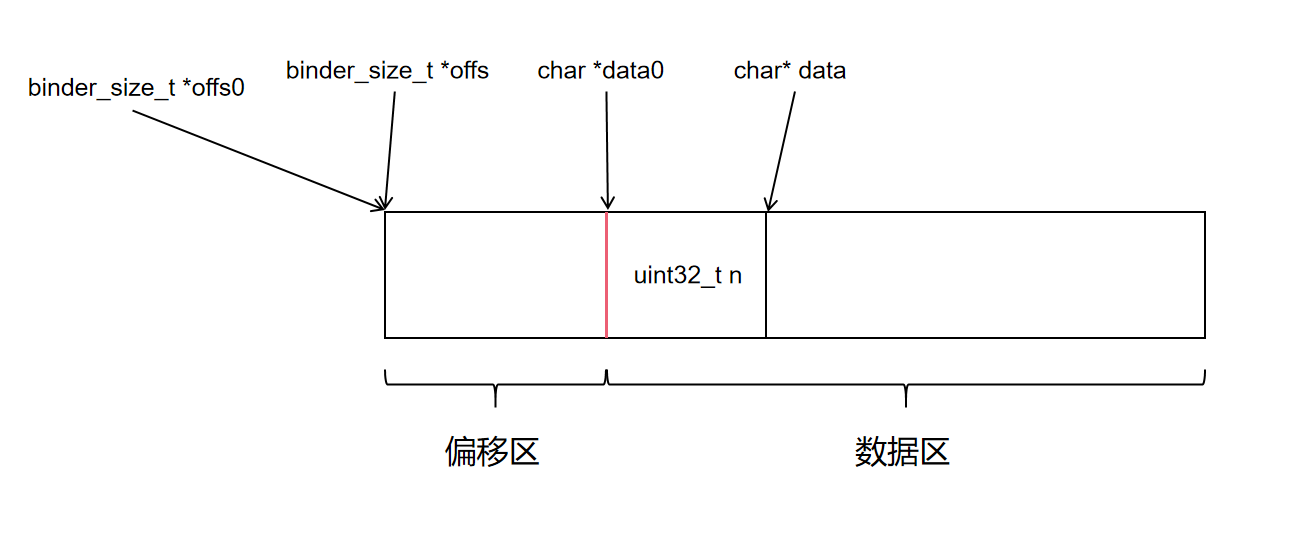
}写入一个 32 位整数的过程如下:
- 在数据区分配 4 字节倍数的数据
- 将整数值写入已分配的内存
写入后一个 uint32_t n 后,内存结构如下图所示:
字符串的写入稍微复杂一点,但是本质原理和写入 unit_32 相同,有兴趣的同学可以自行分析下面的代码:
void bio_put_string16_x(struct binder_io *bio, const char *_str)
{
unsigned char *str = (unsigned char*) _str;
size_t len;
uint16_t *ptr;
//写入一个标记位
if (!str) {
bio_put_uint32(bio, 0xffffffff);
return;
}
len = strlen(_str);
if (len >= (MAX_BIO_SIZE / sizeof(uint16_t))) {
bio_put_uint32(bio, 0xffffffff);
return;
}
/* Note: The payload will carry 32bit size instead of size_t */
//写入字符串长度
bio_put_uint32(bio, len);
//写入字符串内容
ptr = bio_alloc(bio, (len + 1) * sizeof(uint16_t));
if (!ptr)
return;
while (*str)
*ptr++ = *str++;
*ptr++ = 0;
}接下来我们看看,如何在 binder_io 中存一个指针数据。(在服务注册场景下,这个指针指向一个函数,是 server 端收到调用后的回调函数)
void bio_put_obj(struct binder_io *bio, void *ptr)
{
struct flat_binder_object *obj;
//分配内存
obj = bio_alloc_obj(bio);
if (!obj)
return;
obj->flags = 0x7f | FLAT_BINDER_FLAG_ACCEPTS_FDS;
obj->hdr.type = BINDER_TYPE_BINDER;
//ptr 保存在 flat_binder_object 的 binder 成员中
obj->binder = (uintptr_t)ptr;
obj->cookie = 0;
}
static struct flat_binder_object *bio_alloc_obj(struct binder_io *bio)
{
struct flat_binder_object *obj;
//在数据区分配内存
obj = bio_alloc(bio, sizeof(*obj));
//在第一部分保存偏移量
if (obj && bio->offs_avail) {
bio->offs_avail--;
//保存 flat_binder_object 结构在偏移区的偏移值
*bio->offs++ = ((char*) obj) - ((char*) bio->data0);
return obj;
}
bio->flags |= BIO_F_OVERFLOW;
return NULL;
}
struct flat_binder_object {
struct binder_object_header hdr;
__u32 flags;
/* 8 bytes of data. */
union {
binder_uintptr_t binder; /* local object */
__u32 handle; /* remote object */
};
/* extra data associated with local object */
binder_uintptr_t cookie;
};
struct binder_object_header {
__u32 type;
};
struct flat_binder_object {
//hdr.type = BINDER_TYPE_BINDER
struct binder_object_header hdr;
//flags = 0x7f | FLAT_BINDER_FLAG_ACCEPTS_FDS;
__u32 flags;
union {
//binder = (uintptr_t)ptr
//ptr 就是传入的函数指针 hello_service_handler
binder_uintptr_t binder;
__u32 handle;
};
//cookie = 0
binder_uintptr_t cookie;
};对于指针类型,会在数据区分配一个 flat_binder_object 结构体的数据,将指针数据保存在结构体的 binder 成员中。在偏移区将 flat_binder_object 相对 data0 的偏移值保存在 offs 指向的内存,offs 再加 1。完成数据保存后,其内存结构如下图所示:
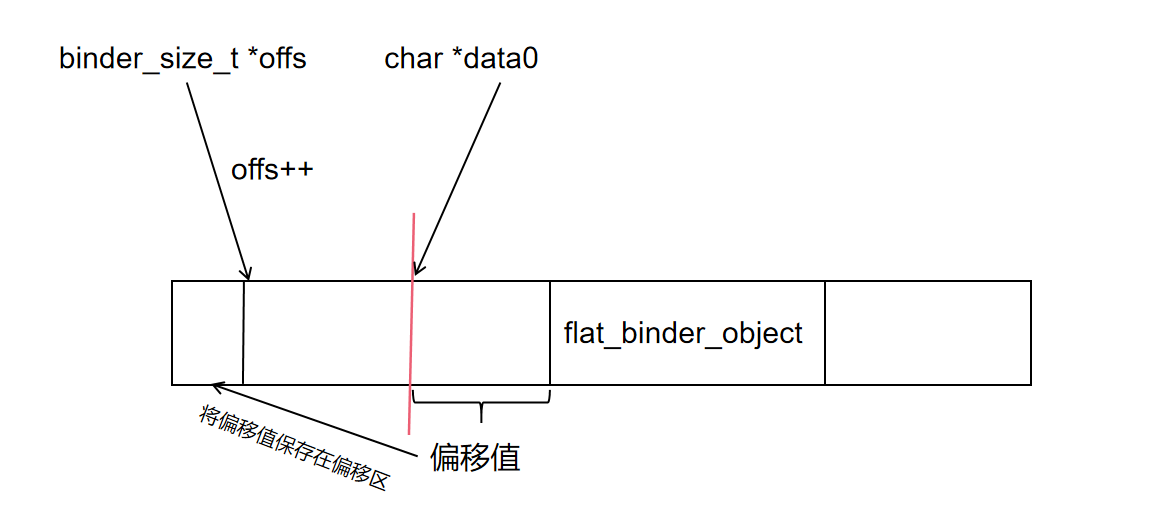
通过上面的分析我们可以画出 svcmgr_publish 中构建的 binder_io 的结构:

3.2 通过 binder_call 发起远程调用
构造好 binder_io 以后,接着就通过 binder_call 发起远程过程调用:
// target 的值为 0 ,用于指示数据发送给哪个进程
// msg 就是我们上面构造的数据结构
// SVC_MGR_ADD_SERVICE 用于指示需要调用的远程函数
binder_call(bs, &msg, &reply, target,SVC_MGR_ADD_SERVICE)
int binder_call(struct binder_state *bs,
struct binder_io *msg, struct binder_io *reply,
uint32_t target, uint32_t code)
{
int res;
//关注点1 binder_io *msg 转为 binder_write_read
//声明数据
struct binder_write_read bwr;
//binder_write_read 内部成员 write_buffer 的结构
struct {
uint32_t cmd;
struct binder_transaction_data txn;
} __attribute__((packed)) writebuf;
unsigned readbuf[32];
//...... 省略非核心代码
//构造 binder_write_read 内部结构 writebuf
// BC_TRANSACTION 表示当前数据是用于发起远程调用
writebuf.cmd = BC_TRANSACTION;
// target 用于找到远程进程,即我们要调用哪个进程的函数
writebuf.txn.target.handle = target;
// code 表示调用哪个函数
writebuf.txn.code = code;
writebuf.txn.flags = 0;
writebuf.txn.data_size = msg->data - msg->data0;
writebuf.txn.offsets_size = ((char*) msg->offs) - ((char*) msg->offs0);
// data 是数据区,指向一个 binder_io 结构体
writebuf.txn.data.ptr.buffer = (uintptr_t)msg->data0;
writebuf.txn.data.ptr.offsets = (uintptr_t)msg->offs0;
//给 write 相关变量赋值
//表示当前进程是写入数据,即发送数据
bwr.write_size = sizeof(writebuf);
bwr.write_consumed = 0;
bwr.write_buffer = (uintptr_t) &writebuf;
hexdump(msg->data0, msg->data - msg->data0);
for (;;) {
//关注点2 写的同时也要读数据
//给 read 相关变量赋值
//同时,我们也要读取返回的结果值
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
//关注点3 发起读写操作
//发送 binder_write_read 数据
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
fprintf(stderr,"binder: ioctl failed (%s)\n", strerror(errno));
goto fail;
}
//省略部分代码 ......
}
fail:
memset(reply, 0, sizeof(*reply));
reply->flags |= BIO_F_IOERROR;
return -1;
}首先构建好需要发送的数据,其格式如下图所示:
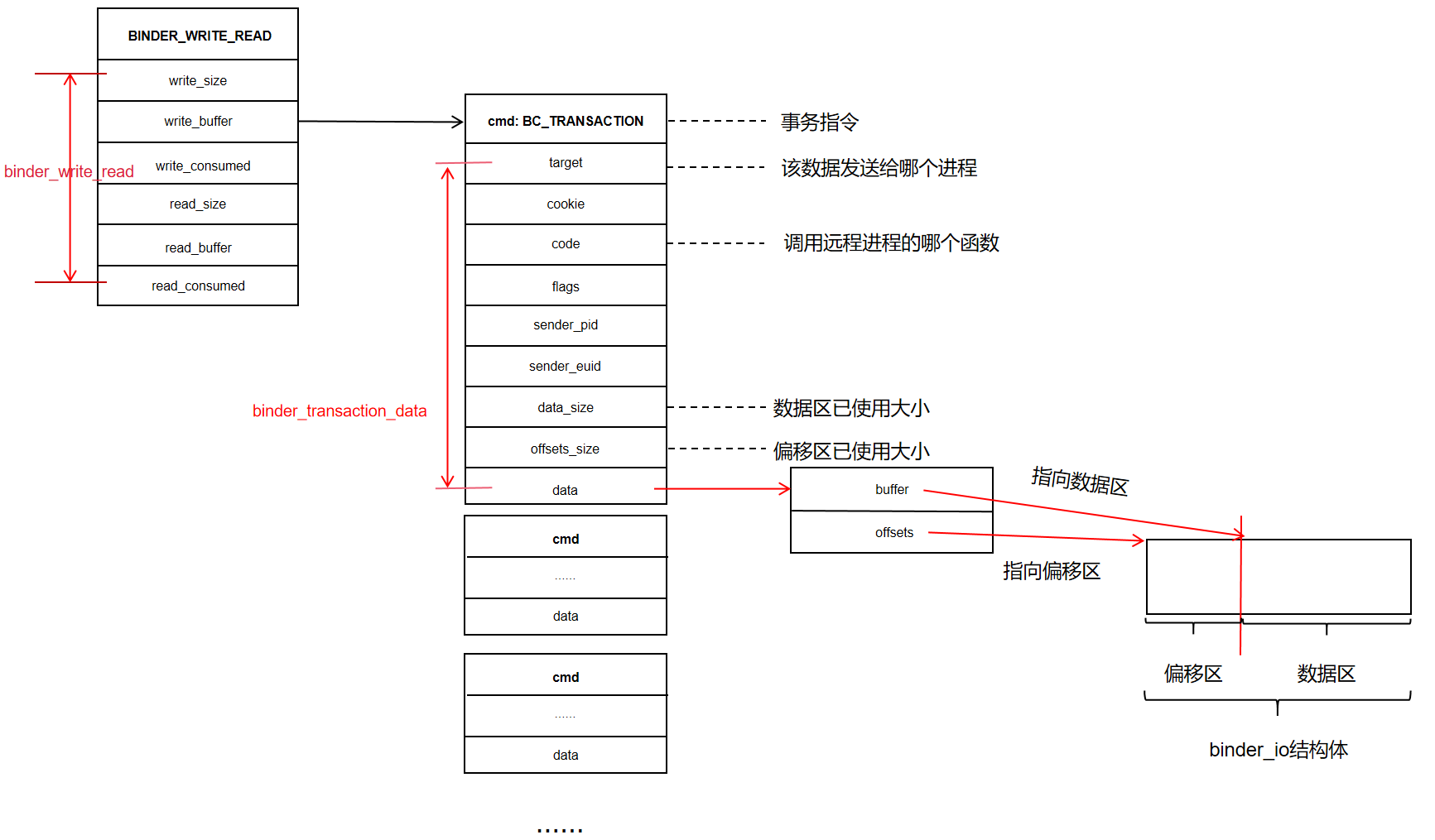
接着调用:
ioctl(bs->fd, BINDER_WRITE_READ, &bwr)软中断陷入内核,经过 vfs 的处理后,最终会调用到 binder 驱动的 binder_ioctl 函数:
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
//获得当前进程的 binder_thread 结构体
//没有就新建一个,并插入 binder_proc 的 threads 链表中
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ: //进 binder_ioctl_write_read 函数
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
//省略不相关case
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
if (thread)
thread->looper_need_return = false;
return ret;
}接着我们看看 binder_ioctl_write_read 的实现:
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
//......
//将应用层的 binder_write_read 拷贝到内核层
//注意,这里只拷贝了指针值,没有拷贝指针指向的数据
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
if (bwr.write_size > 0) {
//走这里
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
//写完以后接着读返回的信息
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
binder_inner_proc_lock(proc);
if (!binder_worklist_empty_ilocked(&proc->todo))
binder_wakeup_proc_ilocked(proc);
binder_inner_proc_unlock(proc);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}接着看看 binder_thread_write 的实现:
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
struct binder_context *context = proc->context;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error.cmd == BR_OK) {
int ret;
//获取到第一个数据 cmd
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
//......
switch (cmd) {
//省略不相关的 case
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
//将 binder_transaction_data 数据读到内核
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
//binder_transaction 发起远程调用
binder_transaction(proc, thread, &tr,
cmd == BC_REPLY, 0);
break;
}
default:
pr_err("%d:%d unknown command %d\n",
proc->pid, thread->pid, cmd);
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0;
}这里通过一个 while 循环解析应用层传过来的数据,数据中 cmd 为 BC_TRANSACTION,进入对于 case,然后调用 binder_transaction 发起远程调用。
接着看 binder_transaction,这个函数巨长,但是其整体流程还是比较清晰:
- 获得目标进程/线程信息
- 将数据拷贝到目标进程所映射的内存中(此时会建立实际的映射关系)
- 将待处理的任务加入 todo 队列,唤醒目标进程/线程
接着我们逐一分析:
获得目标进程/线程信息
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
//一堆临时变量定义,用到再看
int ret;
struct binder_transaction *t;
struct binder_work *tcomplete;
binder_size_t buffer_offset = 0;
binder_size_t off_start_offset, off_end_offset;
binder_size_t off_min;
binder_size_t sg_buf_offset, sg_buf_end_offset;
struct binder_proc *target_proc = NULL;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
struct binder_transaction *in_reply_to = NULL;
struct binder_transaction_log_entry *e;
uint32_t return_error = 0;
uint32_t return_error_param = 0;
uint32_t return_error_line = 0;
binder_size_t last_fixup_obj_off = 0;
binder_size_t last_fixup_min_off = 0;
struct binder_context *context = proc->context;
int t_debug_id = atomic_inc_return(&binder_last_id);
char *secctx = NULL;
u32 secctx_sz = 0;
//......
if (reply) { //不是 reply,不走这
//......
} else { //传入的 handle 值为 0,代表我们要访问 ServiceManager
if (tr->target.handle) {
//......
} else {
mutex_lock(&context->context_mgr_node_lock);
// 从 binder_proc context->binder_context_mgr_node
// 拿到 ServiceManager 对应的 binder_node
target_node = context->binder_context_mgr_node;
//通过 target_node 获得 target_proc
if (target_node)
target_node = binder_get_node_refs_for_txn(
target_node, &target_proc,
&return_error);
else
return_error = BR_DEAD_REPLY;
//......
}
if (!target_node) {
//......
}
//此时,thread->transaction_stack 为空,不会进 if
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) {
//......
}
binder_inner_proc_unlock(proc);
}
//......首先我们拿到保存在 binder_proc->context->binder_context_mgr_node 的 binder_node 节点,该结构体是对 ServiceManager 提供的服务的描述。接着通过 binder_get_node_refs_for_txn 函数,从 binder_node 得到 target_proc。
static struct binder_node *binder_get_node_refs_for_txn(
struct binder_node *node,
struct binder_proc **procp,
uint32_t *error)
{
struct binder_node *target_node = NULL;
binder_node_inner_lock(node);
if (node->proc) {
target_node = node;
binder_inc_node_nilocked(node, 1, 0, NULL);
binder_inc_node_tmpref_ilocked(node);
node->proc->tmp_ref++;
//关键,binder_node -> binder_proc
*procp = node->proc;
} else
*error = BR_DEAD_REPLY;
binder_node_inner_unlock(node);
return target_node;
}从源码可以看出,实际就是从 binder_node 的 proc 成员得到 target_proc。另外,需要注意,当一个函数的参数是二级指针,通常这个参数是用于返回数据的。
接着我们看 binder_transaction 第二阶段:
将数据拷贝到目标进程所映射的内存中
分配缓存,建立映射:
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
//......
//为目标进程binder事务分配空间(后续会加到目标进程/线程的todo队列中,由目标进程/线程处理这个事务)
//struct binder_transaction *t;
t = kzalloc(sizeof(*t), GFP_KERNEL);
//.....
binder_stats_created(BINDER_STAT_TRANSACTION);
spin_lock_init(&t->lock);
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
binder_stats_created(BINDER_STAT_TRANSACTION_COMPLETE);
t->debug_id = t_debug_id;
//主要是通过应用层传入的 binder_transaction_data 来构建 binder_transaction 结构体。
if (!reply && !(tr->flags & TF_ONE_WAY)) //走这
t->from = thread;
else
t->from = NULL;
t->sender_euid = task_euid(proc->tsk);
t->to_proc = target_proc;
//target_thread 目前为空
t->to_thread = target_thread; //目前还是 null
t->code = tr->code;
t->flags = tr->flags;
//......
//分配物理内存并完成映射
t->buffer = binder_alloc_new_buf(&target_proc->alloc, tr->data_size,
tr->offsets_size, extra_buffers_size,
!reply && (t->flags & TF_ONE_WAY));
//......
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
//......这部分代码主要是分配并初始化一个 binder_transaction 结构体。
binder_transaction 结构体用来描述进程间通信过程(事务):
struct binder_transaction {
int debug_id;
//用来描述需要处理的工作事项
struct binder_work work;
//发起事务的线程
struct binder_thread *from;
//事务所依赖的另一个事务
struct binder_transaction *from_parent;
//处理该事务的进程
struct binder_proc *to_proc;
//处理该事务的线程
struct binder_thread *to_thread;
//目标线程下一个需要处理的事务
struct binder_transaction *to_parent;
//1: 表示同步事务,需要等待对方回复
//0: 表示异步事务
unsigned need_reply:1;
//指向为该事务分配的内核缓冲区
struct binder_buffer *buffer;
unsigned int code;
unsigned int flags;
//发起事务线程的优先级
struct binder_priority priority;
//线程在处理事务时,驱动会修改它的优先级以满足源线程和目标Service组建的要求
//在修改之前,会将它原来的线程优先级保存在该成员中,以便线程处理完该事务后可以恢复原来的优先级
struct binder_priority saved_priority;
bool set_priority_called;
kuid_t sender_euid;
binder_uintptr_t security_ctx;
spinlock_t lock;
};这里我们先看一下 binder_alloc_new_buf 是如何分配内存的:
//加锁后调用 binder_alloc_new_buf_locked
// alloc 来自 target_proc
struct binder_buffer *binder_alloc_new_buf(struct binder_alloc *alloc,
size_t data_size,
size_t offsets_size,
size_t extra_buffers_size,
int is_async)
{
struct binder_buffer *buffer;
mutex_lock(&alloc->mutex);
buffer = binder_alloc_new_buf_locked(alloc, data_size, offsets_size,extra_buffers_size, is_async);
mutex_unlock(&alloc->mutex);
return buffer;
}
// alloc 来自 target_proc
static struct binder_buffer *binder_alloc_new_buf_locked(
struct binder_alloc *alloc,
size_t data_size,
size_t offsets_size,
size_t extra_buffers_size,
int is_async)
{
struct rb_node *n = alloc->free_buffers.rb_node;
struct binder_buffer *buffer;
size_t buffer_size;
struct rb_node *best_fit = NULL;
void __user *has_page_addr;
void __user *end_page_addr;
size_t size, data_offsets_size;
int ret;
//......
//ALIGN 宏 用于内存的对齐
//计算需要的内存的大小
//这里需要将size对齐void *(32位下占用4字节,64位下占用8字节)
data_offsets_size = ALIGN(data_size, sizeof(void *)) +
ALIGN(offsets_size, sizeof(void *));
//......
size = data_offsets_size + ALIGN(extra_buffers_size, sizeof(void *));
//.......
/**
* 从上面代码开出,需要的内存大小又三部分组成
* data_size : 应用层传入的数据区大小
* offsets_size:应用层传入的偏移区大小
* extra_buffers_size:这里传入的是 0
*/
//在上一篇说过的 free_async_space
//这里是 oneway 模式,即异步模式,与当前代码情景无关,主要是解释面试题目
//传输的数据的大小不能超过 free_async_space
// free_async_space 默认值是映射区的一半
if (is_async &&
alloc->free_async_space < size + sizeof(struct binder_buffer)) {
binder_alloc_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: binder_alloc_buf size %zd failed, no async space left\n",
alloc->pid, size);
return ERR_PTR(-ENOSPC);
}
//最终计算出一个需要的内存大小
size = max(size, sizeof(void *));
//开始在 alloc-> free_buffers 中找一个大小合适的 binder_buffer
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
BUG_ON(!buffer->free);
//刚开始只有一个 buffer,buffer_size 就是整个缓冲区的大小
buffer_size = binder_alloc_buffer_size(alloc, buffer);
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
}
//......
if (n == NULL) {
//选中的 binder_buffer
buffer = rb_entry(best_fit, struct binder_buffer, rb_node);
buffer_size = binder_alloc_buffer_size(alloc, buffer);
}
//PAGE_MASK 判定 addr 是否是 4096 倍数
//缓存区还剩多少
has_page_addr = (void __user *)
(((uintptr_t)buffer->user_data + buffer_size) & PAGE_MASK);
WARN_ON(n && buffer_size != size);
//要使用的内存的终点位置
end_page_addr =
(void __user *)PAGE_ALIGN((uintptr_t)buffer->user_data + size);
if (end_page_addr > has_page_addr)
end_page_addr = has_page_addr;
//分配物理内存,并完成用户空间与内核空间的映射
ret = binder_update_page_range(alloc, 1, (void __user *)
PAGE_ALIGN((uintptr_t)buffer->user_data), end_page_addr);
//......这里会调用 binder_update_page_range 进行内存的分配与映射:
static int binder_update_page_range(struct binder_alloc *alloc, int allocate,
void __user *start, void __user *end)
{
void __user *page_addr;
unsigned long user_page_addr;
struct binder_lru_page *page;
struct vm_area_struct *vma = NULL;
struct mm_struct *mm = NULL;
bool need_mm = false;
binder_alloc_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: %s pages %pK-%pK\n", alloc->pid,
allocate ? "allocate" : "free", start, end);
if (end <= start)
return 0;
trace_binder_update_page_range(alloc, allocate, start, end);
if (allocate == 0)
goto free_range;
//检查是否有页需要分配
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
page = &alloc->pages[(page_addr - alloc->buffer) / PAGE_SIZE];
if (!page->page_ptr) {
need_mm = true;
break;
}
}
if (need_mm && mmget_not_zero(alloc->vma_vm_mm))
mm = alloc->vma_vm_mm;
if (mm) {
down_read(&mm->mmap_sem);
vma = alloc->vma;
}
if (!vma && need_mm) {
pr_err("%d: binder_alloc_buf failed to map pages in userspace, no vma\n",
alloc->pid);
goto err_no_vma;
}
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
bool on_lru;
size_t index;
index = (page_addr - alloc->buffer) / PAGE_SIZE;
page = &alloc->pages[index];
//page->page_ptr不为NULL说明之前已经分配并映射过了
if (page->page_ptr) {
trace_binder_alloc_lru_start(alloc, index);
on_lru = list_lru_del(&binder_alloc_lru, &page->lru);
WARN_ON(!on_lru);
trace_binder_alloc_lru_end(alloc, index);
continue;
}
if (WARN_ON(!vma))
goto err_page_ptr_cleared;
trace_binder_alloc_page_start(alloc, index);
//分配一个页的物理内存
page->page_ptr = alloc_page(GFP_KERNEL |
__GFP_HIGHMEM |
__GFP_ZERO);
if (!page->page_ptr) {
pr_err("%d: binder_alloc_buf failed for page at %pK\n",
alloc->pid, page_addr);
goto err_alloc_page_failed;
}
page->alloc = alloc;
INIT_LIST_HEAD(&page->lru);
user_page_addr = (uintptr_t)page_addr;
//将物理内存空间映射到目标用户进程虚拟内存空间
ret = vm_insert_page(vma, user_page_addr, page[0].page_ptr);
if (ret) {
pr_err("%d: binder_alloc_buf failed to map page at %lx in userspace\n",
alloc->pid, user_page_addr);
goto err_vm_insert_page_failed;
}
if (index + 1 > alloc->pages_high)
alloc->pages_high = index + 1;
trace_binder_alloc_page_end(alloc, index);
/* vm_insert_page does not seem to increment the refcount */
}
if (mm) {
up_read(&mm->mmap_sem);
mmput(mm);
}
return 0;
free_range:
for (page_addr = end - PAGE_SIZE; page_addr >= start;
page_addr -= PAGE_SIZE) {
bool ret;
size_t index;
index = (page_addr - alloc->buffer) / PAGE_SIZE;
page = &alloc->pages[index];
trace_binder_free_lru_start(alloc, index);
ret = list_lru_add(&binder_alloc_lru, &page->lru);
WARN_ON(!ret);
trace_binder_free_lru_end(alloc, index);
continue;
err_vm_insert_page_failed:
__free_page(page->page_ptr);
page->page_ptr = NULL;
err_alloc_page_failed:
err_page_ptr_cleared:
;
}
err_no_vma:
if (mm) {
up_read(&mm->mmap_sem);
mmput(mm);
}
return vma ? -ENOMEM : -ESRCH;
}代码中的注释写的应该比较清楚了,总之就是先分配物理内存,再将这块物理内存分别映射到内核虚拟空间和用户进程虚拟空间,这样内核虚拟空间与用户进程虚拟空间相当于也间接的建立了映射关系。
关于物理内存的分配以及映射,就是 Linux 内核层的事情了,感兴趣的同学可以再深入往里看看,这里就不再多说了
回过头来,我们接着看 binder_alloc_new_buf_locked:
static struct binder_buffer *binder_alloc_new_buf_locked(
struct binder_alloc *alloc,
size_t data_size,
size_t offsets_size,
size_t extra_buffers_size,
int is_async)
{
//......
//分配好物理内存完成映射后
if (ret) //错误处理
return ERR_PTR(ret);
//缓存区如果没有使用完
//切分 binder_buffer
if (buffer_size != size) {
struct binder_buffer *new_buffer;
new_buffer = kzalloc(sizeof(*buffer), GFP_KERNEL);
if (!new_buffer) {
pr_err("%s: %d failed to alloc new buffer struct\n",
__func__, alloc->pid);
goto err_alloc_buf_struct_failed;
}
new_buffer->user_data = (u8 __user *)buffer->user_data + size;
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1; //binder_buffer 未使用
binder_insert_free_buffer(alloc, new_buffer);
}
rb_erase(best_fit, &alloc->free_buffers);
buffer->free = 0; //binder_buffer 已使用
buffer->allow_user_free = 0;
//将已使用 的 binder_buffer 插入 allocated_buffer
binder_insert_allocated_buffer_locked(alloc, buffer);
binder_alloc_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: binder_alloc_buf size %zd got %pK\n",
alloc->pid, size, buffer);
//上面进行了切分,原来的 binder_buffer 的尺寸相关的值就要修改
buffer->data_size = data_size;
buffer->offsets_size = offsets_size;
buffer->async_transaction = is_async;
buffer->extra_buffers_size = extra_buffers_size;
if (is_async) {
alloc->free_async_space -= size + sizeof(struct binder_buffer);
binder_alloc_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC,
"%d: binder_alloc_buf size %zd async free %zd\n",
alloc->pid, size, alloc->free_async_space);
}
return buffer;
err_alloc_buf_struct_failed:
binder_update_page_range(alloc, 0, (void __user *)
PAGE_ALIGN((uintptr_t)buffer->user_data),
end_page_addr);
return ERR_PTR(-ENOMEM);
}内存的分配和映射部分就完成了,接着我们来看数据是如何拷贝给 ServiceManager 的:
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
//.......
//将用户态的数据(data部分)拷贝到目标进程的 binder_buffer中
if (binder_alloc_copy_user_to_buffer(
&target_proc->alloc,
t->buffer, 0,
(const void __user *)
(uintptr_t)tr->data.ptr.buffer,
tr->data_size)) {
binder_user_error("%d:%d got transaction with invalid data ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
return_error_param = -EFAULT;
return_error_line = __LINE__;
goto err_copy_data_failed;
}
//将用户态的数据(off部分)拷贝到目标进程的 binder_buffer 中
if (binder_alloc_copy_user_to_buffer(
&target_proc->alloc,
t->buffer,
ALIGN(tr->data_size, sizeof(void *)),
(const void __user *)
(uintptr_t)tr->data.ptr.offsets,
tr->offsets_size)) {
binder_user_error("%d:%d got transaction with invalid offsets ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
return_error_param = -EFAULT;
return_error_line = __LINE__;
goto err_copy_data_failed;
}
off_start_offset = ALIGN(tr->data_size, sizeof(void *));
buffer_offset = off_start_offset;
off_end_offset = off_start_offset + tr->offsets_size;
sg_buf_offset = ALIGN(off_end_offset, sizeof(void *));
sg_buf_end_offset = sg_buf_offset + extra_buffers_size;
off_min = 0;
//接着会对数据中的 flat_binder_object 做一些处理
for (buffer_offset = off_start_offset; buffer_offset < off_end_offset;
buffer_offset += sizeof(binder_size_t)) {
struct binder_object_header *hdr;
size_t object_size;
struct binder_object object;
binder_size_t object_offset;
binder_alloc_copy_from_buffer(&target_proc->alloc,
&object_offset,
t->buffer,
buffer_offset,
sizeof(object_offset));
object_size = binder_get_object(target_proc, t->buffer,
object_offset, &object);
if (object_size == 0 || object_offset < off_min) {
binder_user_error("%d:%d got transaction with invalid offset (%lld, min %lld max %lld) or object.\n",
proc->pid, thread->pid,
(u64)object_offset,
(u64)off_min,
(u64)t->buffer->data_size);
return_error = BR_FAILED_REPLY;
return_error_param = -EINVAL;
return_error_line = __LINE__;
goto err_bad_offset;
}
hdr = &object.hdr;
off_min = object_offset + object_size;
switch (hdr->type) {
case BINDER_TYPE_BINDER: //走这里
case BINDER_TYPE_WEAK_BINDER: {
struct flat_binder_object *fp;
fp = to_flat_binder_object(hdr);
//对数据做转换
ret = binder_translate_binder(fp, t, thread);
if (ret < 0) {
return_error = BR_FAILED_REPLY;
return_error_param = ret;
return_error_line = __LINE__;
goto err_translate_failed;
}
//处理后的数据拷贝给目标进程
binder_alloc_copy_to_buffer(&target_proc->alloc,
t->buffer, object_offset,
fp, sizeof(*fp));
} break;
default:
binder_user_error("%d:%d got transaction with invalid object type, %x\n",
proc->pid, thread->pid, hdr->type);
return_error = BR_FAILED_REPLY;
return_error_param = -EINVAL;
return_error_line = __LINE__;
goto err_bad_object_type;
}
}
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
// binder_work 的类型
t->work.type = BINDER_WORK_TRANSACTION;上面的代码通过 binder_translate_binder 对应用层传过来的 flat_binder_object 进行了处理:
//flat_binder_object 定义
struct flat_binder_object {
struct binder_object_header hdr;
__u32 flags;
/* 8 bytes of data. */
union {
binder_uintptr_t binder; /* local object */
__u32 handle; /* remote object */
};
/* extra data associated with local object */
binder_uintptr_t cookie;
};
static int binder_translate_binder(struct flat_binder_object *fp,
struct binder_transaction *t,
struct binder_thread *thread)
{
struct binder_node *node;
struct binder_proc *proc = thread->proc;
struct binder_proc *target_proc = t->to_proc;
struct binder_ref_data rdata;
int ret = 0;
node = binder_get_node(proc, fp->binder);
if (!node) {
node = binder_new_node(proc, fp);
if (!node)
return -ENOMEM;
}
if (fp->cookie != node->cookie) {
binder_user_error("%d:%d sending u%016llx node %d, cookie mismatch %016llx != %016llx\n",
proc->pid, thread->pid, (u64)fp->binder,
node->debug_id, (u64)fp->cookie,
(u64)node->cookie);
ret = -EINVAL;
goto done;
}
if (security_binder_transfer_binder(proc->tsk, target_proc->tsk)) {
ret = -EPERM;
goto done;
}
//创建服务对应的 binder_ref 结构体,并插入 refs_by_node refs_by_desc 两个红黑树中
// 根据插入的顺序计算出 binder_ref 的索引 desc, 并保存到 rdata 中
ret = binder_inc_ref_for_node(target_proc, node,
fp->hdr.type == BINDER_TYPE_BINDER,
&thread->todo, &rdata);
if (ret)
goto done;
//对数据做一些处理
if (fp->hdr.type == BINDER_TYPE_BINDER)
fp->hdr.type = BINDER_TYPE_HANDLE;
else
fp->hdr.type = BINDER_TYPE_WEAK_HANDLE;
fp->binder = 0;
fp->handle = rdata.desc; // handle 值会被 ServiceManager 保存在用户态
fp->cookie = 0;
trace_binder_transaction_node_to_ref(t, node, &rdata);
binder_debug(BINDER_DEBUG_TRANSACTION,
" node %d u%016llx -> ref %d desc %d\n",
node->debug_id, (u64)node->ptr,
rdata.debug_id, rdata.desc);
done:
binder_put_node(node);
return ret;
}
static int binder_inc_ref_for_node(struct binder_proc *proc,
struct binder_node *node,
bool strong,
struct list_head *target_list,
struct binder_ref_data *rdata)
{
struct binder_ref *ref;
struct binder_ref *new_ref = NULL;
int ret = 0;
binder_proc_lock(proc);
ref = binder_get_ref_for_node_olocked(proc, node, NULL);
if (!ref) {
binder_proc_unlock(proc);
new_ref = kzalloc(sizeof(*ref), GFP_KERNEL);
if (!new_ref)
return -ENOMEM;
binder_proc_lock(proc);
ref = binder_get_ref_for_node_olocked(proc, node, new_ref);
}
ret = binder_inc_ref_olocked(ref, strong, target_list);
*rdata = ref->data;
binder_proc_unlock(proc);
if (new_ref && ref != new_ref)
/*
* Another thread created the ref first so
* free the one we allocated
*/
kfree(new_ref);
return ret;
}
static struct binder_ref *binder_get_ref_for_node_olocked(
struct binder_proc *proc,
struct binder_node *node,
struct binder_ref *new_ref)
{
struct binder_context *context = proc->context;
struct rb_node **p = &proc->refs_by_node.rb_node;
struct rb_node *parent = NULL;
struct binder_ref *ref;
struct rb_node *n;
while (*p) {
parent = *p;
ref = rb_entry(parent, struct binder_ref, rb_node_node);
if (node < ref->node)
p = &(*p)->rb_left;
else if (node > ref->node)
p = &(*p)->rb_right;
else
return ref;
}
if (!new_ref)
return NULL;
binder_stats_created(BINDER_STAT_REF);
new_ref->data.debug_id = atomic_inc_return(&binder_last_id);
new_ref->proc = proc;
new_ref->node = node;
rb_link_node(&new_ref->rb_node_node, parent, p);
rb_insert_color(&new_ref->rb_node_node, &proc->refs_by_node);
new_ref->data.desc = (node == context->binder_context_mgr_node) ? 0 : 1;
for (n = rb_first(&proc->refs_by_desc); n != NULL; n = rb_next(n)) {
ref = rb_entry(n, struct binder_ref, rb_node_desc);
if (ref->data.desc > new_ref->data.desc)
break;
new_ref->data.desc = ref->data.desc + 1;
}
p = &proc->refs_by_desc.rb_node;
while (*p) {
parent = *p;
ref = rb_entry(parent, struct binder_ref, rb_node_desc);
if (new_ref->data.desc < ref->data.desc)
p = &(*p)->rb_left;
else if (new_ref->data.desc > ref->data.desc)
p = &(*p)->rb_right;
else
BUG();
}
rb_link_node(&new_ref->rb_node_desc, parent, p);
rb_insert_color(&new_ref->rb_node_desc, &proc->refs_by_desc);
binder_node_lock(node);
hlist_add_head(&new_ref->node_entry, &node->refs);
binder_debug(BINDER_DEBUG_INTERNAL_REFS,
"%d new ref %d desc %d for node %d\n",
proc->pid, new_ref->data.debug_id, new_ref->data.desc,
node->debug_id);
binder_node_unlock(node);
return new_ref;
}至此,数据的拷贝就完成了,接着我们来看第三阶段:
将待处理的任务加入 todo 队列,唤醒目标线程
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
//......
if (reply) {
//......
} else if (!(t->flags & TF_ONE_WAY)) {
BUG_ON(t->buffer->async_transaction != 0);
binder_inner_proc_lock(proc);
//将 tcomplete 插入到事务发起 binder 线程的 todo 队列中
//等 Server 端收到 ServiceManager 的回复后就会执行这个 binder_work
binder_enqueue_deferred_thread_work_ilocked(thread, tcomplete);
//记录一些信息
t->need_reply = 1;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
binder_inner_proc_unlock(proc);
//将t->work插入目标线程的todo队列中并唤醒目标进程
if (!binder_proc_transaction(t, target_proc, target_thread)) {
binder_inner_proc_lock(proc);
binder_pop_transaction_ilocked(thread, t);
binder_inner_proc_unlock(proc);
goto err_dead_proc_or_thread;
}
} else {
//......
}
if (target_thread)
binder_thread_dec_tmpref(target_thread);
binder_proc_dec_tmpref(target_proc);
if (target_node)
binder_dec_node_tmpref(target_node);
/*
* write barrier to synchronize with initialization
* of log entry
*/
smp_wmb();
WRITE_ONCE(e->debug_id_done, t_debug_id);
return;
//......
}binder_proc_transaction 的实现如下:
static bool binder_proc_transaction(struct binder_transaction *t,
struct binder_proc *proc,
struct binder_thread *thread)
{
struct binder_node *node = t->buffer->target_node;
struct binder_priority node_prio;
bool oneway = !!(t->flags & TF_ONE_WAY);
bool pending_async = false;
BUG_ON(!node);
binder_node_lock(node);
node_prio.prio = node->min_priority;
node_prio.sched_policy = node->sched_policy;
if (oneway) {
BUG_ON(thread);
if (node->has_async_transaction) {
pending_async = true;
} else {
node->has_async_transaction = true;
}
}
binder_inner_proc_lock(proc);
//如果目标进程死亡或者目标线程不为NULL且死亡
if (proc->is_dead || (thread && thread->is_dead)) {
binder_inner_proc_unlock(proc);
binder_node_unlock(node);
return false;
}
// thread 为空
// pending_async false
if (!thread && !pending_async) //走这
//从 target_proc 的 waiting_threads 链表中选择第一个作为 target_thread
thread = binder_select_thread_ilocked(proc);
if (thread) {//走这
binder_transaction_priority(thread->task, t, node_prio,
node->inherit_rt);
//把 binder_transaction 插入到 target_thread 的 todo 链表中
binder_enqueue_thread_work_ilocked(thread, &t->work);
} else if (!pending_async) {
binder_enqueue_work_ilocked(&t->work, &proc->todo);
} else {
binder_enqueue_work_ilocked(&t->work, &node->async_todo);
}
if (!pending_async) //走这
//唤醒远程线程
binder_wakeup_thread_ilocked(proc, thread, !oneway /* sync */);
binder_inner_proc_unlock(proc);
binder_node_unlock(node);
return true;
}
//从 target_proc 的 waiting_threads 链表中选择第一个作为 target_thread
static struct binder_thread *
binder_select_thread_ilocked(struct binder_proc *proc)
{
struct binder_thread *thread;
assert_spin_locked(&proc->inner_lock);
thread = list_first_entry_or_null(&proc->waiting_threads,
struct binder_thread,
waiting_thread_node);
if (thread)
list_del_init(&thread->waiting_thread_node);
return thread;
}
//把 binder_transaction 插入到 target_thread 的 todo 链表中
static void
binder_enqueue_thread_work_ilocked(struct binder_thread *thread,
struct binder_work *work)
{
binder_enqueue_work_ilocked(work, &thread->todo);
thread->process_todo = true;
}
static void
binder_enqueue_work_ilocked(struct binder_work *work,
struct list_head *target_list)
{
BUG_ON(target_list == NULL);
BUG_ON(work->entry.next && !list_empty(&work->entry));
list_add_tail(&work->entry, target_list);
}
//唤醒接收端
static void binder_wakeup_thread_ilocked(struct binder_proc *proc,
struct binder_thread *thread,
bool sync)
{
assert_spin_locked(&proc->inner_lock);
if (thread) {
if (sync) //走这
//唤醒 ServiceManager
wake_up_interruptible_sync(&thread->wait);
else
wake_up_interruptible(&thread->wait);
return;
}
binder_wakeup_poll_threads_ilocked(proc, sync);
}至此,binder_transaction 的三个阶段就执行完了:
- 获得目标进程/线程信息
- 将数据拷贝到目标进程所映射的内存中(此时会建立实际的映射关系)
- 将待处理的任务加入 todo 队列,唤醒目标线程
接着我们就来看看 ServiceManager 被唤醒后的操作:
4. ServiceManager 被唤醒
ServiceManager 在 binder_thread_read 函数处,调用进程调度函数进入休眠:
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
int ret = 0;
int wait_for_proc_work;
//......
if (non_block) {
if (!binder_has_work(thread, wait_for_proc_work))
ret = -EAGAIN;
} else {
//ServiceManager 从这里唤醒
ret = binder_wait_for_work(thread, wait_for_proc_work);
}
//把 BINDER_LOOPER_STATE_WAITING 状态取消掉
thread->looper &= ~BINDER_LOOPER_STATE_WAITING;
if (ret)
return ret;
//进入循环解析收到的数据
while (1) {
uint32_t cmd;
struct binder_transaction_data_secctx tr;
struct binder_transaction_data *trd = &tr.transaction_data;
struct binder_work *w = NULL;
struct list_head *list = NULL;
struct binder_transaction *t = NULL;
struct binder_thread *t_from;
size_t trsize = sizeof(*trd);
binder_inner_proc_lock(proc);
//拿到 todo 链表
if (!binder_worklist_empty_ilocked(&thread->todo))
list = &thread->todo; //走这
else if (!binder_worklist_empty_ilocked(&proc->todo) &&
wait_for_proc_work)
list = &proc->todo;
else {
binder_inner_proc_unlock(proc);
/* no data added */
if (ptr - buffer == 4 && !thread->looper_need_return)
goto retry;
break;
}
if (end - ptr < sizeof(tr) + 4) {
binder_inner_proc_unlock(proc);
break;
}
//拿到 Server 端插入的 binder_work
//struct binder_work *w
w = binder_dequeue_work_head_ilocked(list);
if (binder_worklist_empty_ilocked(&thread->todo))
thread->process_todo = false;
switch (w->type) { //执行 binder_work
case BINDER_WORK_TRANSACTION: {
binder_inner_proc_unlock(proc);
//struct binder_transaction *t = NULL;
//从 binder_work 得到 binder_transaction
t = container_of(w, struct binder_transaction, work);
} break;
//省略不相关 case
}
if (!t)
continue;
//通过 binder_transaction 构建 binder_transaction_data
BUG_ON(t->buffer == NULL);
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
struct binder_priority node_prio;
trd->target.ptr = target_node->ptr;
trd->cookie = target_node->cookie;
node_prio.sched_policy = target_node->sched_policy;
node_prio.prio = target_node->min_priority;
binder_transaction_priority(current, t, node_prio,
target_node->inherit_rt);
cmd = BR_TRANSACTION;
} else {
trd->target.ptr = 0;
trd->cookie = 0;
cmd = BR_REPLY;
}
trd->code = t->code;
trd->flags = t->flags;
trd->sender_euid = from_kuid(current_user_ns(), t->sender_euid);
t_from = binder_get_txn_from(t);
if (t_from) {
struct task_struct *sender = t_from->proc->tsk;
trd->sender_pid =
task_tgid_nr_ns(sender,
task_active_pid_ns(current));
} else {
trd->sender_pid = 0;
}
trd->data_size = t->buffer->data_size;
trd->offsets_size = t->buffer->offsets_size;
trd->data.ptr.buffer = (uintptr_t)t->buffer->user_data;
trd->data.ptr.offsets = trd->data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
tr.secctx = t->security_ctx;
if (t->security_ctx) {
cmd = BR_TRANSACTION_SEC_CTX;
trsize = sizeof(tr);
}
//构建好了,开始将数据写回用户态
if (put_user(cmd, (uint32_t __user *)ptr)) {
if (t_from)
binder_thread_dec_tmpref(t_from);
binder_cleanup_transaction(t, "put_user failed",
BR_FAILED_REPLY);
return -EFAULT;
}
ptr += sizeof(uint32_t);
if (copy_to_user(ptr, &tr, trsize)) {
if (t_from)
binder_thread_dec_tmpref(t_from);
binder_cleanup_transaction(t, "copy_to_user failed",
BR_FAILED_REPLY);
return -EFAULT;
}
ptr += trsize;
trace_binder_transaction_received(t);
binder_stat_br(proc, thread, cmd);
binder_debug(BINDER_DEBUG_TRANSACTION,
"%d:%d %s %d %d:%d, cmd %d size %zd-%zd ptr %016llx-%016llx\n",
proc->pid, thread->pid,
(cmd == BR_TRANSACTION) ? "BR_TRANSACTION" :
(cmd == BR_TRANSACTION_SEC_CTX) ?
"BR_TRANSACTION_SEC_CTX" : "BR_REPLY",
t->debug_id, t_from ? t_from->proc->pid : 0,
t_from ? t_from->pid : 0, cmd,
t->buffer->data_size, t->buffer->offsets_size,
(u64)trd->data.ptr.buffer,
(u64)trd->data.ptr.offsets);
if (t_from)
binder_thread_dec_tmpref(t_from);
t->buffer->allow_user_free = 1;
if (cmd != BR_REPLY && !(t->flags & TF_ONE_WAY)) {
binder_inner_proc_lock(thread->proc);
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t;
binder_inner_proc_unlock(thread->proc);
} else {
binder_free_transaction(t);
}
break;
}
done:
*consumed = ptr - buffer;
binder_inner_proc_lock(proc);
if (proc->requested_threads == 0 &&
list_empty(&thread->proc->waiting_threads) &&
proc->requested_threads_started < proc->max_threads &&
(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED)) /* the user-space code fails to */
/*spawn a new thread if we leave this out */) {
proc->requested_threads++;
binder_inner_proc_unlock(proc);
binder_debug(BINDER_DEBUG_THREADS,
"%d:%d BR_SPAWN_LOOPER\n",
proc->pid, thread->pid);
if (put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer))
return -EFAULT;
binder_stat_br(proc, thread, BR_SPAWN_LOOPER);
} else
binder_inner_proc_unlock(proc);
return 0;
}接着程序就会回到用户层:
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;
struct binder_write_read bwr;
uint32_t readbuf[32];
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
readbuf[0] = BC_ENTER_LOOPER;
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
//从这里被唤醒,获取到数据 bwr
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
//解析数据
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
if (res == 0) {
ALOGE("binder_loop: unexpected reply?!\n");
break;
}
if (res < 0) {
ALOGE("binder_loop: io error %d %s\n", res, strerror(errno));
break;
}
}
}
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
{
int r = 1;
uintptr_t end = ptr + (uintptr_t) size;
while (ptr < end) {
uint32_t cmd = *(uint32_t *) ptr;
ptr += sizeof(uint32_t);
#if TRACE
fprintf(stderr,"%s:\n", cmd_name(cmd));
#endif
switch(cmd) {
//省略不相关 case
case BR_TRANSACTION_SEC_CTX:
case BR_TRANSACTION: {
struct binder_transaction_data_secctx txn;
if (cmd == BR_TRANSACTION_SEC_CTX) {
if ((end - ptr) < sizeof(struct binder_transaction_data_secctx)) {
ALOGE("parse: txn too small (binder_transaction_data_secctx)!\n");
return -1;
}
memcpy(&txn, (void*) ptr, sizeof(struct binder_transaction_data_secctx));
ptr += sizeof(struct binder_transaction_data_secctx);
} else /* BR_TRANSACTION */ {
if ((end - ptr) < sizeof(struct binder_transaction_data)) {
ALOGE("parse: txn too small (binder_transaction_data)!\n");
return -1;
}
//又拷贝了一次
memcpy(&txn.transaction_data, (void*) ptr, sizeof(struct binder_transaction_data));
ptr += sizeof(struct binder_transaction_data);
txn.secctx = 0;
}
binder_dump_txn(&txn.transaction_data);
//拿到数据后调用回调函数 func 即传入的 svcmgr_handler
if (func) {
unsigned rdata[256/4];
struct binder_io msg;
struct binder_io reply;
int res;
bio_init(&reply, rdata, sizeof(rdata), 4);
bio_init_from_txn(&msg, &txn.transaction_data);
//返回值是 0
res = func(bs, &txn, &msg, &reply);
if (txn.transaction_data.flags & TF_ONE_WAY) {
binder_free_buffer(bs, txn.transaction_data.data.ptr.buffer);
} else { //走这里,发送返回数据
//res 值为 0
binder_send_reply(bs, &reply, txn.transaction_data.data.ptr.buffer, res);
}
}
break;
}
//省略不相关 case
default:
ALOGE("parse: OOPS %d\n", cmd);
return -1;
}
}
return r;
}
int svcmgr_handler(struct binder_state *bs,
struct binder_transaction_data_secctx *txn_secctx,
struct binder_io *msg,
struct binder_io *reply)
{
struct svcinfo *si;
uint16_t *s;
size_t len;
uint32_t handle;
uint32_t strict_policy;
int allow_isolated;
uint32_t dumpsys_priority;
struct binder_transaction_data *txn = &txn_secctx->transaction_data;
//ALOGI("target=%p code=%d pid=%d uid=%d\n",
// (void*) txn->target.ptr, txn->code, txn->sender_pid, txn->sender_euid);
if (txn->target.ptr != BINDER_SERVICE_MANAGER)
return -1;
if (txn->code == PING_TRANSACTION)
return 0;
// Equivalent to Parcel::enforceInterface(), reading the RPC
// header with the strict mode policy mask and the interface name.
// Note that we ignore the strict_policy and don't propagate it
// further (since we do no outbound RPCs anyway).
strict_policy = bio_get_uint32(msg);
bio_get_uint32(msg); // Ignore worksource header.
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
if ((len != (sizeof(svcmgr_id) / 2)) ||
memcmp(svcmgr_id, s, sizeof(svcmgr_id))) {
fprintf(stderr,"invalid id %s\n", str8(s, len));
return -1;
}
if (sehandle && selinux_status_updated() > 0) {
#ifdef VENDORSERVICEMANAGER
struct selabel_handle *tmp_sehandle = selinux_android_vendor_service_context_handle();
#else
struct selabel_handle *tmp_sehandle = selinux_android_service_context_handle();
#endif
if (tmp_sehandle) {
selabel_close(sehandle);
sehandle = tmp_sehandle;
}
}
//根据 code 调用对于函数
switch(txn->code) {
case SVC_MGR_GET_SERVICE:
case SVC_MGR_CHECK_SERVICE:
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
handle = do_find_service(s, len, txn->sender_euid, txn->sender_pid,
(const char*) txn_secctx->secctx);
if (!handle)
break;
bio_put_ref(reply, handle);
return 0;
case SVC_MGR_ADD_SERVICE: //这里会执行链表插入操作
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
handle = bio_get_ref(msg);
allow_isolated = bio_get_uint32(msg) ? 1 : 0;
dumpsys_priority = bio_get_uint32(msg);
if (do_add_service(bs, s, len, handle, txn->sender_euid, allow_isolated, dumpsys_priority,
txn->sender_pid, (const char*) txn_secctx->secctx))
return -1;
break;
case SVC_MGR_LIST_SERVICES: {
uint32_t n = bio_get_uint32(msg);
uint32_t req_dumpsys_priority = bio_get_uint32(msg);
if (!svc_can_list(txn->sender_pid, (const char*) txn_secctx->secctx, txn->sender_euid)) {
ALOGE("list_service() uid=%d - PERMISSION DENIED\n",
txn->sender_euid);
return -1;
}
si = svclist;
// walk through the list of services n times skipping services that
// do not support the requested priority
while (si) {
if (si->dumpsys_priority & req_dumpsys_priority) {
if (n == 0) break;
n--;
}
si = si->next;
}
if (si) {
bio_put_string16(reply, si->name);
return 0;
}
return -1;
}
default:
ALOGE("unknown code %d\n", txn->code);
return -1;
}
//返回信息,就一个 0
bio_put_uint32(reply, 0);
return 0;
}5. 数据返回过程
接着看如何返回数据:
void binder_send_reply(struct binder_state *bs,
struct binder_io *reply,
binder_uintptr_t buffer_to_free,
int status)
{
struct {
uint32_t cmd_free;
binder_uintptr_t buffer;
uint32_t cmd_reply;
struct binder_transaction_data txn;
} __attribute__((packed)) data;
data.cmd_free = BC_FREE_BUFFER; //先执行一个 free
data.buffer = buffer_to_free;
data.cmd_reply = BC_REPLY; //在来一个 reply
data.txn.target.ptr = 0;
data.txn.cookie = 0;
data.txn.code = 0;
if (status) {
data.txn.flags = TF_STATUS_CODE;
data.txn.data_size = sizeof(int);
data.txn.offsets_size = 0;
data.txn.data.ptr.buffer = (uintptr_t)&status;
data.txn.data.ptr.offsets = 0;
} else { //走这
data.txn.flags = 0;
data.txn.data_size = reply->data - reply->data0;
data.txn.offsets_size = ((char*) reply->offs) - ((char*) reply->offs0);
data.txn.data.ptr.buffer = (uintptr_t)reply->data0;
data.txn.data.ptr.offsets = (uintptr_t)reply->offs0;
}
//发起远程写操作
binder_write(bs, &data, sizeof(data));
}
//通过 ioctl 发起写操作
int binder_write(struct binder_state *bs, void *data, size_t len)
{
struct binder_write_read bwr;
int res;
bwr.write_size = len;
bwr.write_consumed = 0;
bwr.write_buffer = (uintptr_t) data;
bwr.read_size = 0;
bwr.read_consumed = 0;
bwr.read_buffer = 0;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
fprintf(stderr,"binder_write: ioctl failed (%s)\n",
strerror(errno));
}
return res;
}接着陷入内核:
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
/*pr_info("binder_ioctl: %d:%d %x %lx\n",
proc->pid, current->pid, cmd, arg);*/
binder_selftest_alloc(&proc->alloc);
trace_binder_ioctl(cmd, arg);
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
//从 proc 的 threads 红黑树中找 pid 相同的 thread ,没有就新建一个
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ: //走这
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
//省略不相关 case
default:
ret = -EINVAL;
goto err;
}
ret = 0;
//......
return ret;
}
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
//......
if (bwr.write_size > 0) { //走这,写数据
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
binder_inner_proc_lock(proc);
if (!binder_worklist_empty_ilocked(&proc->todo))
binder_wakeup_proc_ilocked(proc);
binder_inner_proc_unlock(proc);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
//......
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
//开始写数据了
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
struct binder_context *context = proc->context;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error.cmd == BR_OK) {
int ret;
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
trace_binder_command(cmd);
if (_IOC_NR(cmd) < ARRAY_SIZE(binder_stats.bc)) {
atomic_inc(&binder_stats.bc[_IOC_NR(cmd)]);
atomic_inc(&proc->stats.bc[_IOC_NR(cmd)]);
atomic_inc(&thread->stats.bc[_IOC_NR(cmd)]);
}
switch (cmd) {
//省略不相关 case
case BC_FREE_BUFFER: { //先走这,主要是完成内存的释放
binder_uintptr_t data_ptr;
struct binder_buffer *buffer;
if (get_user(data_ptr, (binder_uintptr_t __user *)ptr))
return -EFAULT;
ptr += sizeof(binder_uintptr_t);
buffer = binder_alloc_prepare_to_free(&proc->alloc,
data_ptr);
if (IS_ERR_OR_NULL(buffer)) {
if (PTR_ERR(buffer) == -EPERM) {
binder_user_error(
"%d:%d BC_FREE_BUFFER u%016llx matched unreturned or currently freeing buffer\n",
proc->pid, thread->pid,
(u64)data_ptr);
} else {
binder_user_error(
"%d:%d BC_FREE_BUFFER u%016llx no match\n",
proc->pid, thread->pid,
(u64)data_ptr);
}
break;
}
binder_debug(BINDER_DEBUG_FREE_BUFFER,
"%d:%d BC_FREE_BUFFER u%016llx found buffer %d for %s transaction\n",
proc->pid, thread->pid, (u64)data_ptr,
buffer->debug_id,
buffer->transaction ? "active" : "finished");
if (buffer->transaction) {
buffer->transaction->buffer = NULL;
buffer->transaction = NULL;
}
if (buffer->async_transaction && buffer->target_node) {
struct binder_node *buf_node;
struct binder_work *w;
buf_node = buffer->target_node;
binder_node_inner_lock(buf_node);
BUG_ON(!buf_node->has_async_transaction);
BUG_ON(buf_node->proc != proc);
w = binder_dequeue_work_head_ilocked(
&buf_node->async_todo);
if (!w) {
buf_node->has_async_transaction = false;
} else {
binder_enqueue_work_ilocked(
w, &proc->todo);
binder_wakeup_proc_ilocked(proc);
}
binder_node_inner_unlock(buf_node);
}
trace_binder_transaction_buffer_release(buffer);
binder_transaction_buffer_release(proc, buffer, 0, false);
binder_alloc_free_buf(&proc->alloc, buffer);
break;
}
//.......
case BC_TRANSACTION:
case BC_REPLY: { //然后再走这里
struct binder_transaction_data tr;
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
//一样的调用 binder_transaction 返回数据
binder_transaction(proc, thread, &tr,
cmd == BC_REPLY, 0);
break;
}
//省略不相关 case
default:
pr_err("%d:%d unknown command %d\n",
proc->pid, thread->pid, cmd);
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0;
}接下来看一看 binder_alloc_prepare_to_free 函数的具体实现:
struct binder_buffer *binder_alloc_prepare_to_free(struct binder_alloc *alloc,
uintptr_t user_ptr)
{
struct binder_buffer *buffer;
mutex_lock(&alloc->mutex);
buffer = binder_alloc_prepare_to_free_locked(alloc, user_ptr);
mutex_unlock(&alloc->mutex);
return buffer;
}
static struct binder_buffer *binder_alloc_prepare_to_free_locked(
struct binder_alloc *alloc,
uintptr_t user_ptr)
{
struct rb_node *n = alloc->allocated_buffers.rb_node;
struct binder_buffer *buffer;
void __user *uptr;
uptr = (void __user *)user_ptr;
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
BUG_ON(buffer->free);
if (uptr < buffer->user_data)
n = n->rb_left;
else if (uptr > buffer->user_data)
n = n->rb_right;
else {
/*
* Guard against user threads attempting to
* free the buffer when in use by kernel or
* after it's already been freed.
*/
if (!buffer->allow_user_free)
return ERR_PTR(-EPERM);
buffer->allow_user_free = 0;
return buffer;
}
}
return NULL;
}接着我们再来看看返回数据时,binder_transaction 是如何执行的,流程和之前的分析基本一直,只是都是走的 reply 部分:
//发起数据传输
binder_transaction(proc, thread, &tr,cmd == BC_REPLY, 0);
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
int ret;
struct binder_transaction *t;
struct binder_work *tcomplete;
binder_size_t buffer_offset = 0;
binder_size_t off_start_offset, off_end_offset;
binder_size_t off_min;
binder_size_t sg_buf_offset, sg_buf_end_offset;
struct binder_proc *target_proc = NULL;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
struct binder_transaction *in_reply_to = NULL;
struct binder_transaction_log_entry *e;
uint32_t return_error = 0;
uint32_t return_error_param = 0;
uint32_t return_error_line = 0;
binder_size_t last_fixup_obj_off = 0;
binder_size_t last_fixup_min_off = 0;
struct binder_context *context = proc->context;
int t_debug_id = atomic_inc_return(&binder_last_id);
char *secctx = NULL;
u32 secctx_sz = 0;
e = binder_transaction_log_add(&binder_transaction_log);
e->debug_id = t_debug_id;
e->call_type = reply ? 2 : !!(tr->flags & TF_ONE_WAY);
e->from_proc = proc->pid;
e->from_thread = thread->pid;
e->target_handle = tr->target.handle;
e->data_size = tr->data_size;
e->offsets_size = tr->offsets_size;
e->context_name = proc->context->name;
if (reply) { //走这
binder_inner_proc_lock(proc);
// ServiceManager 收到数据时做了相关保存
// if (cmd != BR_REPLY && !(t->flags & TF_ONE_WAY)) {
// binder_inner_proc_lock(thread->proc);
// t->to_parent = thread->transaction_stack;
// t->to_thread = thread;
// thread->transaction_stack = t;
// binder_inner_proc_unlock(thread->proc);
// }
//in_reply_to 就是之前发过来的数据
in_reply_to = thread->transaction_stack ;
//错误情况的处理
if (in_reply_to == NULL) {
//......
}
if (in_reply_to->to_thread != thread) {
//......
}
//出栈,恢复成空
thread->transaction_stack = in_reply_to->to_parent;
binder_inner_proc_unlock(proc);
//通过收到的 binder_transaction 得到当前需要的 target_thread
target_thread = binder_get_txn_from_and_acq_inner(in_reply_to);
//......
target_proc = target_thread->proc;
target_proc->tmp_ref++;
binder_inner_proc_unlock(target_thread->proc);
} else {
//......
}
if (target_thread)
e->to_thread = target_thread->pid;
e->to_proc = target_proc->pid;
/* TODO: reuse incoming transaction for reply */
t = kzalloc(sizeof(*t), GFP_KERNEL);
if (t == NULL) {
return_error = BR_FAILED_REPLY;
return_error_param = -ENOMEM;
return_error_line = __LINE__;
goto err_alloc_t_failed;
}
binder_stats_created(BINDER_STAT_TRANSACTION);
spin_lock_init(&t->lock);
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
if (tcomplete == NULL) {
return_error = BR_FAILED_REPLY;
return_error_param = -ENOMEM;
return_error_line = __LINE__;
goto err_alloc_tcomplete_failed;
}
binder_stats_created(BINDER_STAT_TRANSACTION_COMPLETE);
t->debug_id = t_debug_id;
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
t->sender_euid = task_euid(proc->tsk);
t->to_proc = target_proc;
t->to_thread = target_thread;
t->code = tr->code;
t->flags = tr->flags;
if (!(t->flags & TF_ONE_WAY) &&
binder_supported_policy(current->policy)) {
/* Inherit supported policies for synchronous transactions */
t->priority.sched_policy = current->policy;
t->priority.prio = current->normal_prio;
} else {
/* Otherwise, fall back to the default priority */
t->priority = target_proc->default_priority;
}
if (target_node && target_node->txn_security_ctx) {
u32 secid;
security_task_getsecid(proc->tsk, &secid);
ret = security_secid_to_secctx(secid, &secctx, &secctx_sz);
if (ret) {
return_error = BR_FAILED_REPLY;
return_error_param = ret;
return_error_line = __LINE__;
goto err_get_secctx_failed;
}
extra_buffers_size += ALIGN(secctx_sz, sizeof(u64));
}
trace_binder_transaction(reply, t, target_node);
//分配内存并完成映射
t->buffer = binder_alloc_new_buf(&target_proc->alloc, tr->data_size,
tr->offsets_size, extra_buffers_size,
!reply && (t->flags & TF_ONE_WAY));
if (IS_ERR(t->buffer)) {
/*
* -ESRCH indicates VMA cleared. The target is dying.
*/
return_error_param = PTR_ERR(t->buffer);
return_error = return_error_param == -ESRCH ?
BR_DEAD_REPLY : BR_FAILED_REPLY;
return_error_line = __LINE__;
t->buffer = NULL;
goto err_binder_alloc_buf_failed;
}
if (secctx) {
size_t buf_offset = ALIGN(tr->data_size, sizeof(void *)) +
ALIGN(tr->offsets_size, sizeof(void *)) +
ALIGN(extra_buffers_size, sizeof(void *)) -
ALIGN(secctx_sz, sizeof(u64));
t->security_ctx = (uintptr_t)t->buffer->user_data + buf_offset;
binder_alloc_copy_to_buffer(&target_proc->alloc,
t->buffer, buf_offset,
secctx, secctx_sz);
security_release_secctx(secctx, secctx_sz);
secctx = NULL;
}
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
trace_binder_transaction_alloc_buf(t->buffer);
//将用户空间的数据拷贝到内核空间的 t->buffer,这里拷贝的是数据区
if (binder_alloc_copy_user_to_buffer(
&target_proc->alloc,
t->buffer, 0,
(const void __user *)
(uintptr_t)tr->data.ptr.buffer,
tr->data_size)) {
binder_user_error("%d:%d got transaction with invalid data ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
return_error_param = -EFAULT;
return_error_line = __LINE__;
goto err_copy_data_failed;
}
//将用户空间的数据拷贝到内核空间的 t->buffer,这里拷贝的是偏移区
if (binder_alloc_copy_user_to_buffer(
&target_proc->alloc,
t->buffer,
ALIGN(tr->data_size, sizeof(void *)),
(const void __user *)
(uintptr_t)tr->data.ptr.offsets,
tr->offsets_size)) {
binder_user_error("%d:%d got transaction with invalid offsets ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
return_error_param = -EFAULT;
return_error_line = __LINE__;
goto err_copy_data_failed;
}
//......
off_start_offset = ALIGN(tr->data_size, sizeof(void *));
buffer_offset = off_start_offset;
off_end_offset = off_start_offset + tr->offsets_size;
sg_buf_offset = ALIGN(off_end_offset, sizeof(void *));
sg_buf_end_offset = sg_buf_offset + extra_buffers_size;
off_min = 0;
for (buffer_offset = off_start_offset; buffer_offset < off_end_offset;
buffer_offset += sizeof(binder_size_t)) { //每次读 64 字节
struct binder_object_header *hdr;
size_t object_size;
struct binder_object object;
binder_size_t object_offset;
binder_alloc_copy_from_buffer(&target_proc->alloc,
&object_offset,
t->buffer,
buffer_offset,
sizeof(object_offset));
object_size = binder_get_object(target_proc, t->buffer,
object_offset, &object);
if (object_size == 0 || object_offset < off_min) {
binder_user_error("%d:%d got transaction with invalid offset (%lld, min %lld max %lld) or object.\n",
proc->pid, thread->pid,
(u64)object_offset,
(u64)off_min,
(u64)t->buffer->data_size);
return_error = BR_FAILED_REPLY;
return_error_param = -EINVAL;
return_error_line = __LINE__;
goto err_bad_offset;
}
hdr = &object.hdr;
off_min = object_offset + object_size;
switch (hdr->type) {
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {
struct flat_binder_object *fp;
fp = to_flat_binder_object(hdr);
ret = binder_translate_binder(fp, t, thread);
if (ret < 0) {
return_error = BR_FAILED_REPLY;
return_error_param = ret;
return_error_line = __LINE__;
goto err_translate_failed;
}
binder_alloc_copy_to_buffer(&target_proc->alloc,
t->buffer, object_offset,
fp, sizeof(*fp));
} break;
default:
binder_user_error("%d:%d got transaction with invalid object type, %x\n",
proc->pid, thread->pid, hdr->type);
return_error = BR_FAILED_REPLY;
return_error_param = -EINVAL;
return_error_line = __LINE__;
goto err_bad_object_type;
}
}
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
t->work.type = BINDER_WORK_TRANSACTION;
if (reply) {
//插入 binder_work
// 唤醒 Server 端
binder_enqueue_thread_work(thread, tcomplete);
binder_inner_proc_lock(target_proc);
if (target_thread->is_dead) {
binder_inner_proc_unlock(target_proc);
goto err_dead_proc_or_thread;
}
BUG_ON(t->buffer->async_transaction != 0);
binder_pop_transaction_ilocked(target_thread, in_reply_to);
binder_enqueue_thread_work_ilocked(target_thread, &t->work);
binder_inner_proc_unlock(target_proc);
wake_up_interruptible_sync(&target_thread->wait);
binder_restore_priority(current, in_reply_to->saved_priority);
binder_free_transaction(in_reply_to);
} else if (!(t->flags & TF_ONE_WAY)) {
//......
} else {
//........
}
if (target_thread)
binder_thread_dec_tmpref(target_thread);
binder_proc_dec_tmpref(target_proc);
if (target_node)
binder_dec_node_tmpref(target_node);
/*
* write barrier to synchronize with initialization
* of log entry
*/
smp_wmb();
WRITE_ONCE(e->debug_id_done, t_debug_id);
return;
//......
}接着 Server 端被唤醒:
Server 端在完成写操作后,会立即进入读操作,并阻塞,当 ServiceManager 发回返回数据时被唤醒:
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
//......
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
//写完以后接着读返回的信息,阻塞在这里
//ServiceManager 将其从这里唤醒
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
binder_inner_proc_lock(proc);
if (!binder_worklist_empty_ilocked(&proc->todo))
binder_wakeup_proc_ilocked(proc);
binder_inner_proc_unlock(proc);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}接着就回到了应用层:
int binder_call(struct binder_state *bs,
struct binder_io *msg, struct binder_io *reply,
uint32_t target, uint32_t code)
{
//......
for (;;) {
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
//从这里唤醒
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
fprintf(stderr,"binder: ioctl failed (%s)\n", strerror(errno));
goto fail;
}
//解析返回的数据
res = binder_parse(bs, reply, (uintptr_t) readbuf, bwr.read_consumed, 0);
if (res == 0) {
return 0;
}
if (res < 0) {
goto fail;
}
}
//......
}解析返回数据:
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
{
int r = 1;
uintptr_t end = ptr + (uintptr_t) size;
while (ptr < end) {
uint32_t cmd = *(uint32_t *) ptr;
ptr += sizeof(uint32_t);
#if TRACE
fprintf(stderr,"%s:\n", cmd_name(cmd));
#endif
switch(cmd) {
//...... 省略部分代码
case BR_REPLY: {
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
if ((end - ptr) < sizeof(*txn)) {
ALOGE("parse: reply too small!\n");
return -1;
}
binder_dump_txn(txn);
if (bio) {
//数据放到 bio 中,即上一层传入的 reply
bio_init_from_txn(bio, txn);
bio = 0;
} else {
/* todo FREE BUFFER */
}
ptr += sizeof(*txn);
r = 0;
break;
}
//省略部分代码 ......
}
}
return r;
}binder_parse 返回 0,收到的数据保存在 reply 中:
int binder_call(struct binder_state *bs,
struct binder_io *msg, struct binder_io *reply,
uint32_t target, uint32_t code)
{
//binder_parse 返回
res = binder_parse(bs, reply, (uintptr_t) readbuf, bwr.read_consumed, 0);
if (res == 0) return 0; // 返回值是 0
if (res < 0) goto fail;
//......
}binder_call 返回到 svcmgr_publish
int svcmgr_publish(struct binder_state *bs, uint32_t target, const char *name, void *ptr)
{
//......
//binder_call 返回 0
if (binder_call(bs, &msg, &reply, target, SVC_MGR_ADD_SERVICE)) {
//fprintf(stderr, "svcmgr_public 远程调用失败\n");
return -1;
}
//解析返回值
//解析出的值是 0 表示调用成功
status = bio_get_uint32(&reply); //调用成功返回0
//远程调用结束,通知驱动清理内存
binder_done(bs, &msg, &reply);
return status; //返回 0 给 main 主程序,调用成功
}最后调用 binder_done 通知驱动清理内存:
void binder_done(struct binder_state *bs,
__unused struct binder_io *msg,
struct binder_io *reply)
{
struct {
uint32_t cmd;
uintptr_t buffer;
} __attribute__((packed)) data;
if (reply->flags & BIO_F_SHARED) {
data.cmd = BC_FREE_BUFFER;
data.buffer = (uintptr_t) reply->data0;
binder_write(bs, &data, sizeof(data));
reply->flags = 0;
}
}这里陷入内核执行一个 BC_FREE_BUFFER 操作,上文已做分析,这里不在重复
至此,服务的注册过程就完成了