本文系统源码版本:
- AOSP 分支:android-10.0.0_r41
- Kernel 分支:android-goldfish-4.14-gchips
对于驱动的分析,我要主要关注程序执行的流程,包括了用户态与内核态,其次也要重点关注内核态相关数据结构的变化,这里我们先给出结论,再通过源码逐一分析:
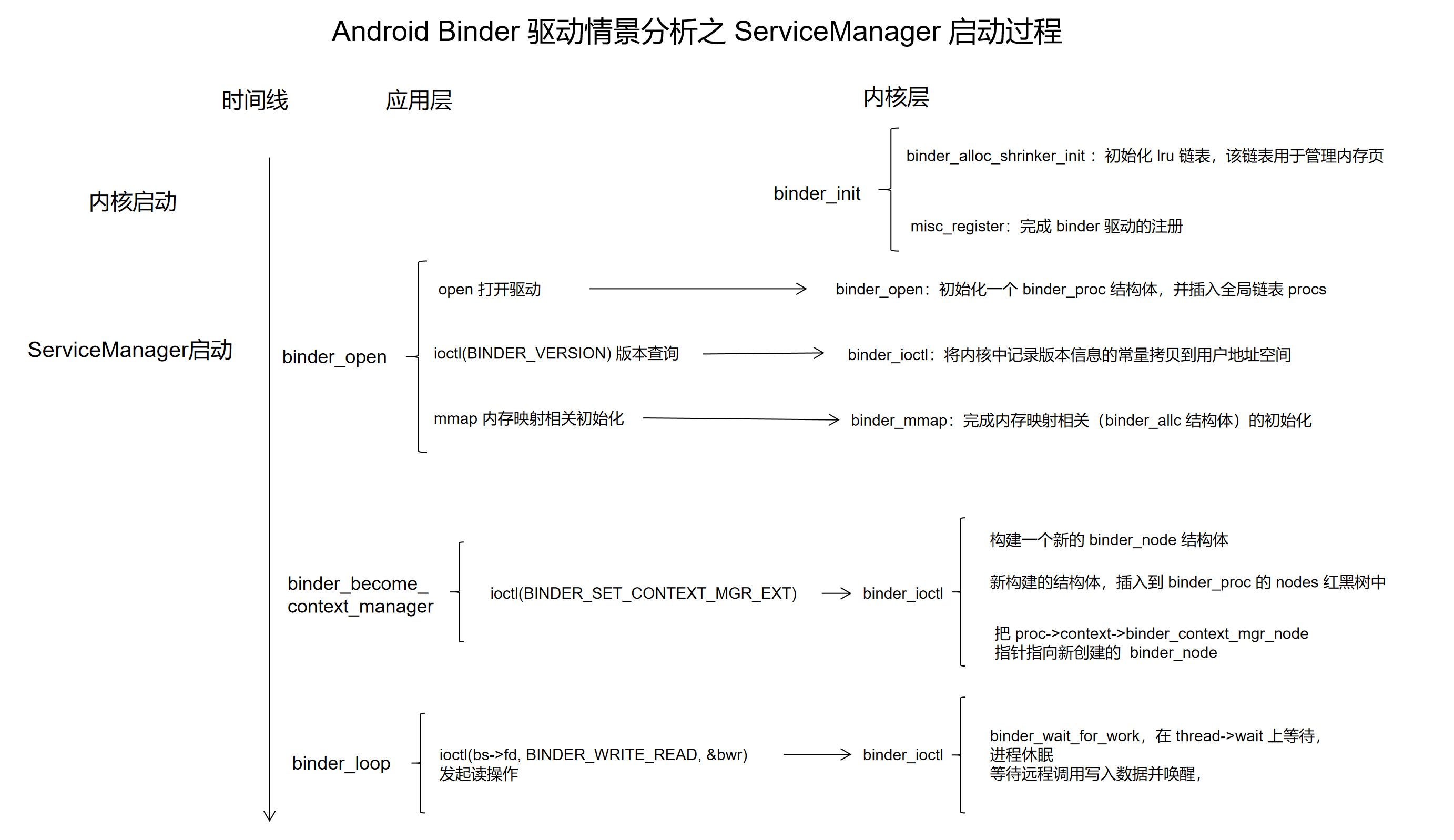
# 回顾 ServiceManager 应用层
ServerManager由系统实现,对应的代码在:frameworks/native/cmds/servicemanager/service_manager.c
int main(int argc, char** argv)
{
struct binder_state *bs;
char *driver;
if (argc > 1) {
driver = argv[1];
} else {
driver = "/dev/binder";
}
//关注点1,初始化 binder 驱动
bs = binder_open(driver, 128*1024);
if (!bs) {
//省略 VENDORSERVICEMANAGER 相关代码 ......
ALOGE("failed to open binder driver %s\n", driver);
return -1;
}
//关注点2, 注册当前进程为 context_manager
if (binder_become_context_manager(bs)) {
ALOGE("cannot become context manager (%s)\n", strerror(errno));
return -1;
}
// 省略 selinux 相关代码 ......
//关注点3
//进入循环,等待远程调用
//svcmgr_handler 是一个函数指针,是远程调用的回调函数
binder_loop(bs, svcmgr_handler);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 1. Binder 驱动的初始化
内核启动时,会加载各类驱动,对于 binder 驱动,会执行 binder_init 函数, 完成驱动的注册与初始化。
// drivers/android/binder.c
//为便于理解删减部分非核心代码
static int __init binder_init(void)
{
int ret;
char *device_name, *device_names, *device_tmp;
struct binder_device *device;
struct hlist_node *tmp;
// 用于初始化一个 lru 链表 struct list_lru binder_alloc_lru;
// 链表成员是 binder_lru_page
// 用于内存页的回收
ret = binder_alloc_shrinker_init();
if (ret)
return ret;
//省略部分 debugfs 相关代码
//binder_devices_param 的值是 "binder,hwbinder,vndbinder"
// 对应三个设备文件 /dev/binder /dev/hwbinder /dev/vndbinder
device_names = kzalloc(strlen(binder_devices_param) + 1, GFP_KERNEL);
if (!device_names) {
ret = -ENOMEM;
goto err_alloc_device_names_failed;
}
strcpy(device_names, binder_devices_param);
device_tmp = device_names;
while ((device_name = strsep(&device_tmp, ","))) {
//注册驱动程序
ret = init_binder_device(device_name);
if (ret)
goto err_init_binder_device_failed;
}
//......
}
//binder 注册为一个杂项驱动
//杂项驱动通过一个 misc_register 函数注册,需要提供一个 miscdevice 结构体
//和之前介绍的字符驱动类似
static int __init init_binder_device(const char *name)
{
int ret;
struct binder_device *binder_device;
binder_device = kzalloc(sizeof(*binder_device), GFP_KERNEL);
if (!binder_device)
return -ENOMEM;
binder_device->miscdev.fops = &binder_fops;
binder_device->miscdev.minor = MISC_DYNAMIC_MINOR;
binder_device->miscdev.name = name;
binder_device->context.binder_context_mgr_uid = INVALID_UID;
binder_device->context.name = name;
mutex_init(&binder_device->context.context_mgr_node_lock);
//注册驱动
ret = misc_register(&binder_device->miscdev);
if (ret < 0) {
kfree(binder_device);
return ret;
}
hlist_add_head(&binder_device->hlist, &binder_devices);
return ret;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
这里涉及了 linux kernel 的 Shrinker 机制,这里先简单介绍一下:
内核的核心功能之一是缓存(cache)管理;通过维护各种级别的缓存,内核能够显著提高性能。但是要小心不能让缓存无限制地增长,否则它们最终将耗尽所有内存。为了应对该问题,内核提供了一套 “shrinker” 接口(shrink 原意有收缩、减小的意思,在这里表示通过回收内存减小缓存体积),通过该机制,内存管理子系统可以(通过回调的方式)请求(相关缓存的管理者)丢弃部分缓存项,从而释放内存以供其他用途使用。
在 binder 驱动中使用了 Shrinker 机制来回收内存页:
//函数调用
ret = binder_alloc_shrinker_init();
//函数实现
int binder_alloc_shrinker_init(void)
{
//binder_alloc_lru 是一个 lru 链表,链表的节点是 binder_lru_page
int ret = list_lru_init(&binder_alloc_lru);
if (ret == 0) {
//注册 shrinker 结构体
ret = register_shrinker(&binder_shrinker);
if (ret)
list_lru_destroy(&binder_alloc_lru);
}
return ret;
}
//binder_alloc_lru 是一个 lru 链表,链表的节点是 binder_lru_page
struct list_lru binder_alloc_lru;
struct binder_lru_page {
struct list_head lru;
struct page *page_ptr;
struct binder_alloc *alloc;
};
//需要使用者定义两个回调函数
// 内存管理子系统会在内存紧张的时候调用这两个函数来回收内存,有点 jvm 内存回收那感觉
//count_objects 用于计算能够被回收的对象的个数上限
//scan_objects 用于回收内存
static struct shrinker binder_shrinker = {
.count_objects = binder_shrink_count,
.scan_objects = binder_shrink_scan,
.seeks = DEFAULT_SEEKS,
};
static unsigned long
binder_shrink_count(struct shrinker *shrink, struct shrink_control *sc)
{
//直接返回 lru 链表的节点数
unsigned long ret = list_lru_count(&binder_alloc_lru);
return ret;
}
static unsigned long
binder_shrink_scan(struct shrinker *shrink, struct shrink_control *sc)
{
unsigned long ret;
//list_lru_walk 用于遍历 lru 链表,并对每个链表节点执行 binder_alloc_free_page 函数
//binder_alloc_free_page 函数用于回收物理内存
ret = list_lru_walk(&binder_alloc_lru, binder_alloc_free_page,
NULL, sc->nr_to_scan);
return ret;
}
//回收内存页,了解即可
enum lru_status binder_alloc_free_page(struct list_head *item,
struct list_lru_one *lru,
spinlock_t *lock,
void *cb_arg)
{
struct mm_struct *mm = NULL;
//拿到 item 对应的节点信息
struct binder_lru_page *page = container_of(item,
struct binder_lru_page,
lru);
struct binder_alloc *alloc;
uintptr_t page_addr;
size_t index;
struct vm_area_struct *vma;
alloc = page->alloc;
if (!mutex_trylock(&alloc->mutex))
goto err_get_alloc_mutex_failed;
if (!page->page_ptr)
goto err_page_already_freed;
index = page - alloc->pages;
page_addr = (uintptr_t)alloc->buffer + index * PAGE_SIZE;
vma = binder_alloc_get_vma(alloc);
if (vma) {
if (!mmget_not_zero(alloc->vma_vm_mm))
goto err_mmget;
mm = alloc->vma_vm_mm;
if (!down_write_trylock(&mm->mmap_sem))
goto err_down_write_mmap_sem_failed;
}
list_lru_isolate(lru, item);
spin_unlock(lock);
if (vma) {
trace_binder_unmap_user_start(alloc, index);
zap_page_range(vma, page_addr, PAGE_SIZE);
trace_binder_unmap_user_end(alloc, index);
up_write(&mm->mmap_sem);
mmput(mm);
}
trace_binder_unmap_kernel_start(alloc, index);
__free_page(page->page_ptr);
page->page_ptr = NULL;
trace_binder_unmap_kernel_end(alloc, index);
spin_lock(lock);
mutex_unlock(&alloc->mutex);
return LRU_REMOVED_RETRY;
err_down_write_mmap_sem_failed:
mmput_async(mm);
err_mmget:
err_page_already_freed:
mutex_unlock(&alloc->mutex);
err_get_alloc_mutex_failed:
return LRU_SKIP;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
binder 驱动在 init 部分主要完成了以下工作:
- 初始化 lru 链表,该链表用于管理内存页,并注册了 shrinker 结构体,在内存紧张时,对内存进行回收
- 注册 binder 驱动
# 2. ServiceManager 启动过程
我们首先看一下,应用层 ServiceManager 对应的源码:
int main(int argc, char** argv)
{
struct binder_state *bs;
char *driver;
if (argc > 1) {
driver = argv[1];
} else {
driver = "/dev/binder";
}
//关注点1
bs = binder_open(driver, 128*1024);
//删减了 VENDORSERVICEMANAGER 相关内容
if (!bs) {
ALOGE("failed to open binder driver %s\n", driver);
return -1;
}
//关注点2
if (binder_become_context_manager(bs)) {
ALOGE("cannot become context manager (%s)\n", strerror(errno));
return -1;
}
//删减了 selinux 相关内容
//关注点3
binder_loop(bs, svcmgr_handler);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 2.1 binder_open
关注点1:在这里调用 binder_open 来完成 binder 初始化操作
struct binder_state *binder_open(const char* driver, size_t mapsize)
{
struct binder_state *bs; //用于存需要返回的值
struct binder_version vers;
bs = malloc(sizeof(*bs));
if (!bs) {
errno = ENOMEM;
return NULL;
}
//关注点4 打开 /dev/binder,拿到内核返回的句柄
bs->fd = open(driver, O_RDWR | O_CLOEXEC);
if (bs->fd < 0) {
fprintf(stderr,"binder: cannot open %s (%s)\n",
driver, strerror(errno));
goto fail_open;
}
//关注点5 查询版本
if ((ioctl(bs->fd, BINDER_VERSION, &vers) == -1) ||
(vers.protocol_version != BINDER_CURRENT_PROTOCOL_VERSION)) {
fprintf(stderr,
"binder: kernel driver version (%d) differs from user space version (%d)\n",
vers.protocol_version, BINDER_CURRENT_PROTOCOL_VERSION);
goto fail_open;
}
//关注点6 内存映射相关的初始化
bs->mapsize = mapsize;
bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);
if (bs->mapped == MAP_FAILED) {
fprintf(stderr,"binder: cannot map device (%s)\n",
strerror(errno));
goto fail_map;
}
return bs;
fail_map:
close(bs->fd);
fail_open:
free(bs);
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
在 虚拟内存与 Linux 文件访问接口 (opens new window) 中分享了这么一个图:
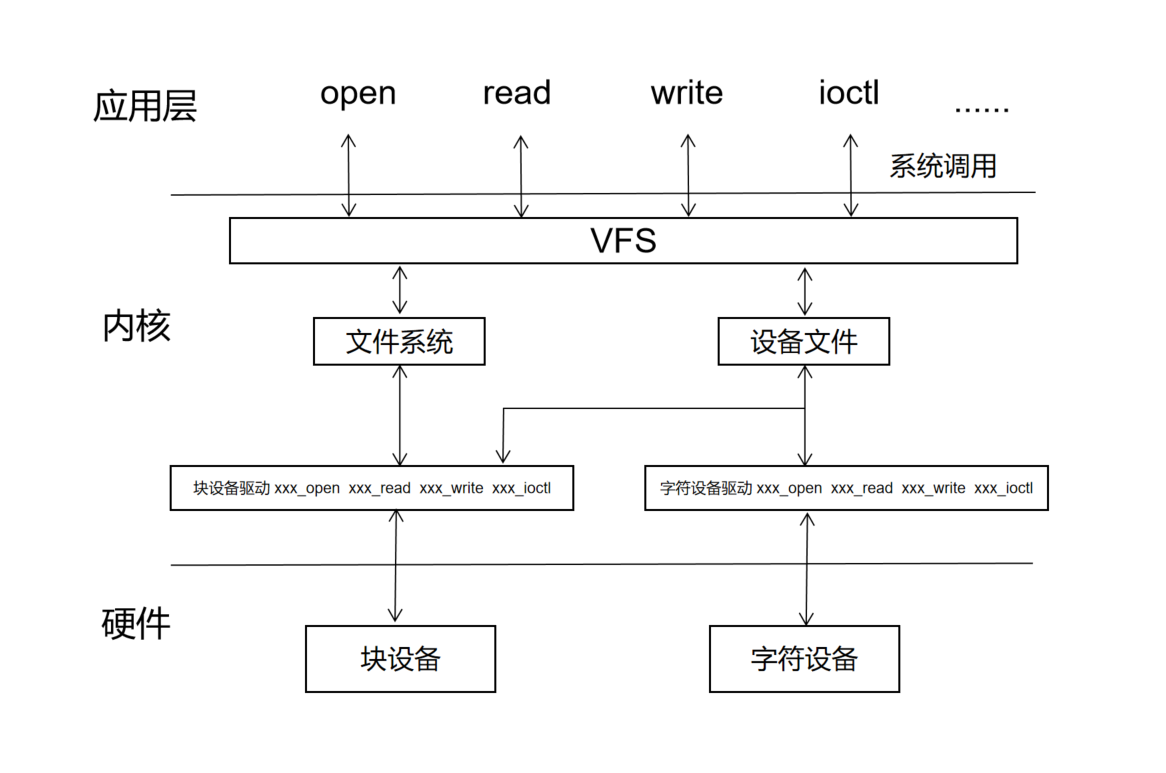
当我们调用系统调用函数 open 后,会触发一个软中断,处理器切换到内核态,并执行对应的中断处理函数,中断处理程序会执行 vfs 中的代码,做一些初始化工作,对传入的参数做一些处理(了解即可),然后就会调用到 binder 驱动程序中注册的 binder_open 函数了:
//为方便理解,删减部分非核心代码
//binder_open 函数主要功能是初始化一个 binder_proc 结构体
//filp 是 vfs 创建的一个 file 文件,是对 /dev/binder 文件的描述
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
struct binder_device *binder_dev;
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
//proc->tsk 赋值为 current->group_leader
//current->group_leader 是主线程对应的 task_struct 结构体
get_task_struct(current->group_leader);
proc->tsk = current->group_leader;
//初始化 proc->todo 链表,链表节点的类型是 binder_work
INIT_LIST_HEAD(&proc->todo);
//获得驱动初始化时定义的结构体,并保存上下文信息到 proc->context 中
binder_dev = container_of(filp->private_data, struct binder_device,
miscdev);
proc->context = &binder_dev->context;
//初始化 proc->alloc, alloc 类型是 binder_alloc,用于管理 binder_buffer
// binder_buffer 描述一次 RPC 交互过程中使用到的内存
binder_alloc_init(&proc->alloc);
proc->pid = current->group_leader->pid;
//初始化两个链表
//死亡通知队列
INIT_LIST_HEAD(&proc->delivered_death);
//空闲线程队列
INIT_LIST_HEAD(&proc->waiting_threads);
//将初始化好的 binder_proc 保存到 filp->private_data 中
//方便 binder_ioctl binder_mmap 函数获取到 binder_proc
filp->private_data = proc;
//将 binder_proc 添加到全局 hash 表 binder_procs 中
hlist_add_head(&proc->proc_node, &binder_procs);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
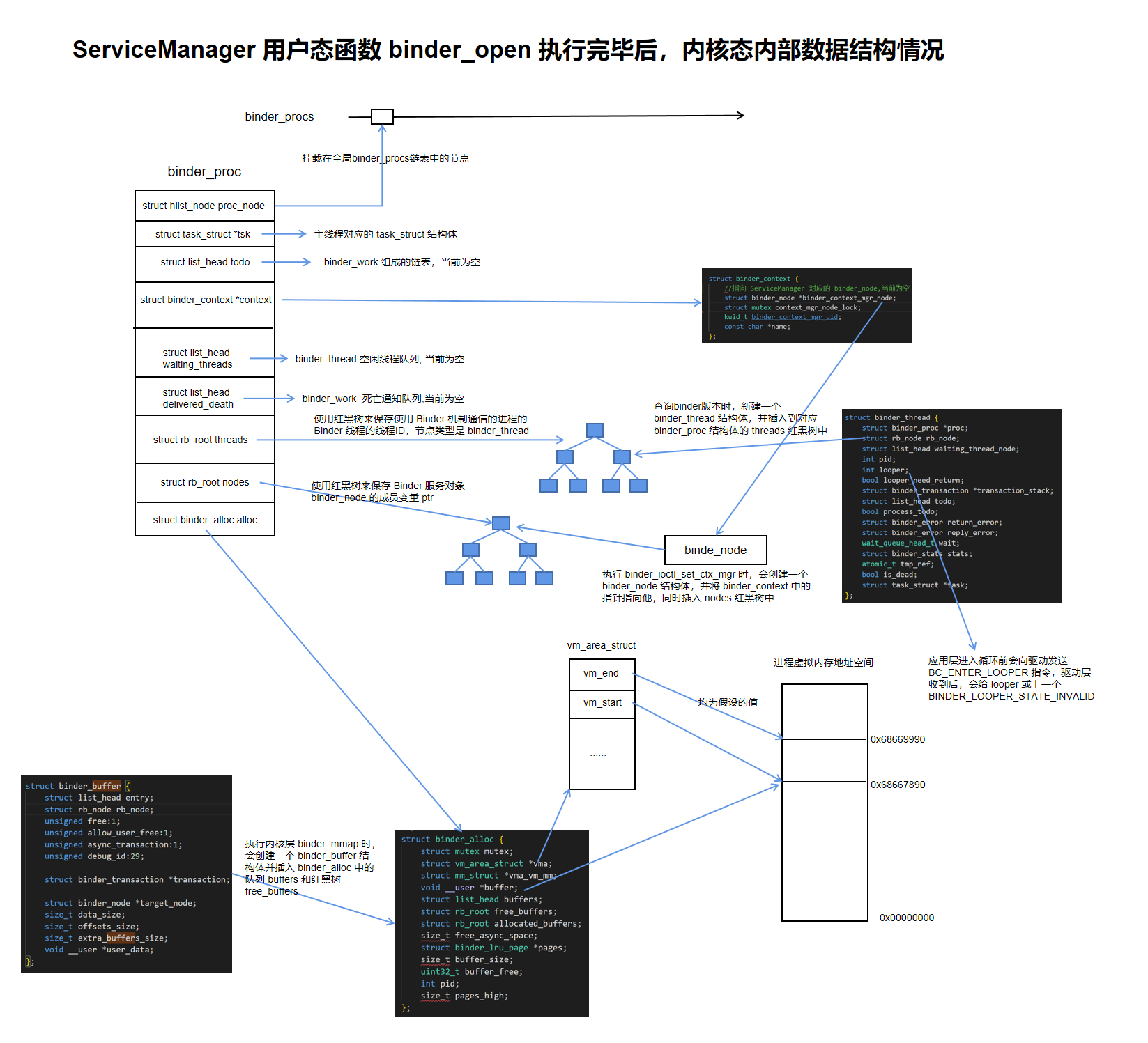
binder_open 函数主要工作是创建并初始化 binder_proc 结构体,并将其插入全局链表 binder_procs。接下来我们来看看相关的数据结构:
//全局哈希链表 binder_procs,用于保存 binder_proc
static HLIST_HEAD(binder_procs);
// binder_proc 是 Binder 驱动中用于描述用户态进程的结构体
// 添加了注释的部分就是 binder_open 中初始化的成员
struct binder_proc {
struct hlist_node proc_node; //挂载在全局 binder_proc s链表中的节点。
struct rb_root threads; //使用红黑树来保存使用 Binder 机制通信的进程的 Binder 线程池的线程ID
struct rb_root nodes; //使用红黑树来保存 Binder 服务对象 binder_node 的成员变量 ptr
struct rb_root refs_by_desc; //使用红黑树来保存 binder_node 对应的 binder_ref 的成员变量 desc
struct rb_root refs_by_node; //使用红黑树来保存 binder_node 对应的 binder_ref 的成员变量 node
struct list_head waiting_threads; //空闲线程队列
int pid; //当前进程的 pid
struct task_struct *tsk; //当前主线程的 task_struct
struct files_struct *files; //打开文件结构体
struct mutex files_lock;
struct hlist_node deferred_work_node; //挂载在全局延迟工作项链表binder_deferred_list中的节点
int deferred_work; //描述延迟工作项的具体类型
bool is_dead; //process is dead and awaiting free when outstanding transactions are cleaned up
struct list_head todo; //进程待处理工作项队列
struct binder_stats stats; //统计进程接收到的进程间通信请求次数
struct list_head delivered_death; //死亡通知队列
int max_threads; //保存Binder驱动程序最多可以主动请求进程注册的线程数量
int requested_threads; //number of binder threads requested but not yet started. In current implementation, can only be 0 or 1
int requested_threads_started; //number binder threads started
int tmp_ref; //temporary reference to indicate proc is in use
struct binder_priority default_priority; //default scheduler priority
struct dentry *debugfs_entry; //debugfs node
struct binder_alloc alloc; //用于管理 binder_buffer,binder_buffer 是对一次 RPC 调用使用的内存的描述
struct binder_context *context; //驱动上下文
spinlock_t inner_lock;
spinlock_t outer_lock;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
- binder_proc 是 binder 驱动中用于描述用户态进程的结构体
- binder_open 的主要工作是初始化一个 binder_proc 结构体,并将其插入到全局链表 binder_procs 中
接着我们看关注点 5 ,应用程序调用 ioctl 向内核查询 binder 版本信息:
ioctl(bs->fd, BINDER_VERSION, &vers)
和 open 系统调用相同,ioctl 最终会执行到 binder 驱动的 binder_ioctl 函数:
ioctl() -> vfs -> binder_ioctl
binder_ioctl 的实现如下:
//drivers/android/binder.c
//为方便理解,删减部分非核心代码
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
//binder_open 时,会把 binder_proc 保存到 filp->private_data
//这里从 filp->private_data 中取出
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
//binder_get_thread 会构建一个新的 binder_thread, 并插入 binder_proc.threads 红黑树
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
//应用层
switch (cmd) {
//......
//省略不相关的 case
case BINDER_VERSION: { //走这里
struct binder_version __user *ver = ubuf;
if (size != sizeof(struct binder_version)) {
ret = -EINVAL;
goto err;
}
//binder 中版本定义为一个常量
//拷贝到应用层的指针
if (put_user(BINDER_CURRENT_PROTOCOL_VERSION,
&ver->protocol_version)) {
ret = -EINVAL;
goto err;
}
break;
}
//......
//省略不相关的 case
}
//......
return ret;
}
static struct binder_thread *binder_get_thread(struct binder_proc *proc)
{
struct binder_thread *thread;
struct binder_thread *new_thread;
binder_inner_proc_lock(proc);
thread = binder_get_thread_ilocked(proc, NULL);
binder_inner_proc_unlock(proc);
if (!thread) {
new_thread = kzalloc(sizeof(*thread), GFP_KERNEL);
if (new_thread == NULL)
return NULL;
binder_inner_proc_lock(proc);
thread = binder_get_thread_ilocked(proc, new_thread);
binder_inner_proc_unlock(proc);
if (thread != new_thread)
kfree(new_thread);
}
return thread;
}
static struct binder_thread *binder_get_thread_ilocked(
struct binder_proc *proc, struct binder_thread *new_thread)
{
struct binder_thread *thread = NULL;
struct rb_node *parent = NULL;
struct rb_node **p = &proc->threads.rb_node;
printk("binder_get_thread_ilocked, *p is %p", *p);
while (*p) {
parent = *p;
thread = rb_entry(parent, struct binder_thread, rb_node);
if (current->pid < thread->pid)
p = &(*p)->rb_left;
else if (current->pid > thread->pid)
p = &(*p)->rb_right;
else
return thread;
}
if (!new_thread)
return NULL;
thread = new_thread;
binder_stats_created(BINDER_STAT_THREAD);
thread->proc = proc;
thread->pid = current->pid;
get_task_struct(current);
thread->task = current;
atomic_set(&thread->tmp_ref, 0);
init_waitqueue_head(&thread->wait);
INIT_LIST_HEAD(&thread->todo);
rb_link_node(&thread->rb_node, parent, p);
rb_insert_color(&thread->rb_node, &proc->threads);
thread->looper_need_return = true;
thread->return_error.work.type = BINDER_WORK_RETURN_ERROR;
thread->return_error.cmd = BR_OK;
thread->reply_error.work.type = BINDER_WORK_RETURN_ERROR;
thread->reply_error.cmd = BR_OK;
INIT_LIST_HEAD(&new_thread->waiting_thread_node);
return thread;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
上述代码涉及到了 binder_thread 结构体,用于描述用户态的一个线程:
struct binder_thread {
struct binder_proc *proc; //指向该binder线程的宿主进程
struct rb_node rb_node; //挂载到宿主进程binder_proc的成员变量threads红黑树的节点
struct list_head waiting_thread_node; //挂载到宿主进程binder_proc的成员变量 waiting_threads 的节点
int pid; //binder线程pid
int looper; //binder线程运行状态
bool looper_need_return; //loop 中的线程是否需要退出驱动
struct binder_transaction *transaction_stack; //需要线程处理的事务栈
struct list_head todo; //binder线程待处理队列
bool process_todo; //todo 中的 binder_work 是否应该被处理
struct binder_error return_error; //当前线程的事务错误
struct binder_error reply_error; //目标线程的事务错误
wait_queue_head_t wait; // Binder 线程会睡眠在wait描述的等待队列中
struct binder_stats stats; //统计该Binder线程接收到的进程间通信请求次数
atomic_t tmp_ref; //指示线程正在使用的临时引用
bool is_dead; // thread is dead and awaiting free when outstanding transactions are cleaned up
struct task_struct *task; //当前 thread 对应的 task_struct
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在内核中 binder 的驱动版本定义为一个常量 BINDER_CURRENT_PROTOCOL_VERSION,驱动通过 put_user 函数将这个常量的值拷贝到用户空间。
接着我们再看看关注点 6,这里调用 mmap,来完成内存映射相关的初始化,和 open ioctl 系统调用相同, mmap 最终会执行到 binder 驱动的 binder_mmap 函数:
mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0) -> vfs -> binder_mmap
接着我们看下 binder_mmap 的具体实现:
//filp 是 vfs 中的 filp 是同一个结构体
//vma 是 vfs 中根据应用层传入的 mapsize 构建的结构体,用于描述一段用户空间虚拟内存
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
//binder_open 中将构建好的 binder_proc 保存到了 filp->private_data 中
struct binder_proc *proc = filp->private_data;
const char *failure_string;
//得和binder_open 是同一个进程
if (proc->tsk != current->group_leader)
return -EINVAL;
// 映射区最多分配 4m
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
//......
//配置 vma
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags |= VM_DONTCOPY | VM_MIXEDMAP;
vma->vm_flags &= ~VM_MAYWRITE;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
//初始化 binder_proc 中的 binder_alloc
ret = binder_alloc_mmap_handler(&proc->alloc, vma);
if (ret)
return ret;
// 将当前进程 task_struct 中的 files_struct 赋值给 binder_proc 成员的 proc->files
mutex_lock(&proc->files_lock);
proc->files = get_files_struct(current);
mutex_unlock(&proc->files_lock);
return 0;
err_bad_arg:
pr_err("%s: %d %lx-%lx %s failed %d\n", __func__,
proc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
}
// 初始化 binder_proc 中的 binder_alloc
// binder_alloc 用于操作 binder_buffer 的结构体
// binder_buffer 描述一次 RPC 交互过程中使用到的内存
int binder_alloc_mmap_handler(struct binder_alloc *alloc,
struct vm_area_struct *vma)
{
int ret;
const char *failure_string;
struct binder_buffer *buffer;
//已经分配就退出
mutex_lock(&binder_alloc_mmap_lock);
if (alloc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
//alloc->buffer 指向用户空间起始位置
alloc->buffer = (void __user *)vma->vm_start;
mutex_unlock(&binder_alloc_mmap_lock);
//pages 类型是 binder_lru_page 用于管理内存中的页
alloc->pages = kzalloc(sizeof(alloc->pages[0]) *
((vma->vm_end - vma->vm_start) / PAGE_SIZE),
GFP_KERNEL);
if (alloc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
//记录映射区域的大小
alloc->buffer_size = vma->vm_end - vma->vm_start;
//初始化 binder_buffer
buffer = kzalloc(sizeof(*buffer), GFP_KERNEL);
if (!buffer) {
ret = -ENOMEM;
failure_string = "alloc buffer struct";
goto err_alloc_buf_struct_failed;
}
buffer->user_data = alloc->buffer; //就是 vma->vm_start,用户空间映射区的起始位置
// 初始化完成的 binder_alloc 保存到 binder_alloc 的
list_add(&buffer->entry, &alloc->buffers);
buffer->free = 1;
//将初始化好的 binder_buffer 插入 alloc.free_buffers 红黑树,
binder_insert_free_buffer(alloc, buffer);
//free_async_space 异步调用可以使用的内存大小
alloc->free_async_space = alloc->buffer_size / 2;
//alloc->vma = vma
binder_alloc_set_vma(alloc, vma);
mmgrab(alloc->vma_vm_mm);
return 0;
err_alloc_buf_struct_failed:
kfree(alloc->pages);
alloc->pages = NULL;
err_alloc_pages_failed:
mutex_lock(&binder_alloc_mmap_lock);
alloc->buffer = NULL;
err_already_mapped:
mutex_unlock(&binder_alloc_mmap_lock);
pr_err("%s: %d %lx-%lx %s failed %d\n", __func__,
alloc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
可以看出,binder_mmap 主要工作是完成 binder_proc 的成员 binder_allc 结构体的初始化,没有分配物理内存与映射:
struct binder_buffer {
struct list_head entry; // alloc->buffers 链表中的节点
struct rb_node rb_node; // alloc.free_buffers 红黑树中的节点
unsigned free:1; // binder_buffer 空闲时,值为 true
unsigned allow_user_free:1; // 值为 true,表示允许被清理
unsigned async_transaction:1; // 值为 true,表示 binder_buffer 用于一个异步的远程调用
unsigned debug_id:29;
struct binder_transaction *transaction; //RPC 过程中传输的数据
struct binder_node *target_node; //binder_node 用于描述一个远程服务,target_node 就是当前 RPC 需要使用的服务
size_t data_size; //数据区大小
size_t offsets_size; //偏移区大小
size_t extra_buffers_size; //额外区大小
void __user *user_data;
};
struct binder_alloc {
struct mutex mutex;
struct vm_area_struct *vma;
struct mm_struct *vma_vm_mm;
void __user *buffer; //vma->vm_start,指向用户空间的开始位置
struct list_head buffers; //创建好一个 binder_buffer,并插入 buffers 链表
struct rb_root free_buffers; //创建好的 binder_buffer,也要插入 free_buffers 红黑树
struct rb_root allocated_buffers;
//free_async_space 异步调用可以使用的内存大小
size_t free_async_space;
struct binder_lru_page *pages; //分配好内存,用于管理内存中的页
size_t buffer_size;
uint32_t buffer_free;
int pid;
size_t pages_high;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
这里涉及一个常见的面试题,binder 支持传递的最大内存是多少?
// 映射区最多分配 4m
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
2
3
在驱动层面的代码看,最多可以分配 4m 的映射区,当然具体多少还和应用层传递过来的参数有关。比如再 ServiceManager 中 mmap 传入的是 128*1024 即 128KB。binder_alloc 结构体中的成员变量 free_async_space 的值也会影响到传输数据的大小,这部分我们会在后面远程过程调用部分讲解。
# 2.2 binder_become_context_manager
关注点 2 处,调用 binder_become_context_manager 函数,将当前进程设置为 context_manager:
int binder_become_context_manager(struct binder_state *bs)
{
//构建需要发送的数据 flat_binder_object
struct flat_binder_object obj;
memset(&obj, 0, sizeof(obj));
obj.flags = FLAT_BINDER_FLAG_TXN_SECURITY_CTX;
//向 Binder 驱动发送数据
int result = ioctl(bs->fd, BINDER_SET_CONTEXT_MGR_EXT, &obj);
//如果失败,使用原始方式再次调用 ioctl
// fallback to original method
if (result != 0) {
android_errorWriteLog(0x534e4554, "121035042");
result = ioctl(bs->fd, , 0);
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
ioctl 最终会调用到 binder 驱动中的 binder_ioctl:
ioctl(bs->fd, BINDER_SET_CONTEXT_MGR_EXT, &obj) -> vfs -> binder_ioctl
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
/*pr_info("binder_ioctl: %d:%d %x %lx\n",
proc->pid, current->pid, cmd, arg);*/
binder_selftest_alloc(&proc->alloc);
trace_binder_ioctl(cmd, arg);
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
//省略不相关的 case
case BINDER_SET_CONTEXT_MGR_EXT: { //代码走这里
struct flat_binder_object fbo;
//数据拷贝到内核区
if (copy_from_user(&fbo, ubuf, sizeof(fbo))) {
ret = -EINVAL;
goto err;
}
//binder_ioctl_set_ctx_mgr
ret = binder_ioctl_set_ctx_mgr(filp, &fbo);
if (ret)
goto err;
break;
}
//省略不相关的 case
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
if (thread)
thread->looper_need_return = false;
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret && ret != -ERESTARTSYS)
pr_info("%d:%d ioctl %x %lx returned %d\n", proc->pid, current->pid, cmd, arg, ret);
err_unlocked:
trace_binder_ioctl_done(ret);
return ret;
}
接着会调用到 binder_ioctl_set_ctx_mgr:
```c
//为方便理解,省略部分非核心代码
static int binder_ioctl_set_ctx_mgr(struct file *filp,
struct flat_binder_object *fbo)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
struct binder_context *context = proc->context;
struct binder_node *new_node;
mutex_lock(&context->context_mgr_node_lock);
// binder_node 结构体用于描述一个应用层 bidner 服务
//binder_new_node 函数会初始化一个 binder_node,并插入 binder_proc 的 nodes 红黑树中
new_node = binder_new_node(proc, fbo);
if (!new_node) {
ret = -ENOMEM;
goto out;
}
// 将新构建的 binder_node 赋值给 proc->context 的 binder_context_mgr_node 成员
context->binder_context_mgr_node = new_node;
binder_node_unlock(new_node);
binder_put_node(new_node);
out:
mutex_unlock(&context->context_mgr_node_lock);
return ret;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
binder_ioctl_set_ctx_mgr 用于将当前进程设置为ServiceManager, binder_node 结构体用于描述一个应用层 bidner 服务,binder_new_node 函数会构建一个新的 binder_node 结构体,并插入到 binder_proc 的 nodes 红黑树中。 接着会把 proc->context->binder_context_mgr_node 指针指向新创建的 node。
# 2.3 binder_loop
接着 ServiceManager 调用 binder_loop 进入读数据,处理数据的循环:
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;
//ioctl 读写数据类型
struct binder_write_read bwr;
uint32_t readbuf[32];
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
//告诉驱动,应用程序要进入循环了
readbuf[0] = BC_ENTER_LOOPER;
//ioctl 的基本封装
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
//结合上面 bwr 的赋值,这里是要读数据
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
//向驱动发起读操作
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
//省略后续代码......
}
}
//binder_write 是对 ioctl + BINDER_WRITE_READ 写操作的简单封装
int binder_write(struct binder_state *bs, void *data, size_t len)
{
struct binder_write_read bwr;
int res;
bwr.write_size = len;
bwr.write_consumed = 0;
bwr.write_buffer = (uintptr_t) data;
bwr.read_size = 0;
bwr.read_consumed = 0;
bwr.read_buffer = 0;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
fprintf(stderr,"binder_write: ioctl failed (%s)\n",
strerror(errno));
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
首先是调用 binder_write,告诉驱动应用程序进入循环,调用路线如下:
binder_write -> ioctl(bs->fd, BINDER_WRITE_READ, &bwr) -> binder_ioctl
//readbuf[0] = BC_ENTER_LOOPER;
//ioctl 的基本封装
//binder_write(bs, readbuf, sizeof(uint32_t));
//res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
//......
switch (cmd) {
case BINDER_WRITE_READ: //代码走这里
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
//省略不相关 case
default:
ret = -EINVAL;
goto err;
}
//......
}
//接着调用 binder_ioctl_write_read
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
//将应用层的数据拷贝到内核中
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
//......
if (bwr.write_size > 0) {
//接着调用 binder_thread_write 写数据
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
//......
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
//binder_thread_write
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
struct binder_context *context = proc->context;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error.cmd == BR_OK) {
int ret;
//cmd 就是应用层传入的 BC_ENTER_LOOPER
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
//......
switch (cmd) {
case BC_ENTER_LOOPER:
if (thread->looper & BINDER_LOOPER_STATE_REGISTERED) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
}
//操作很简单,给 thread->looper 或一个 BINDER_LOOPER_STATE_ENTERED
thread->looper |= BINDER_LOOPER_STATE_ENTERED;
break;
default:
pr_err("%d:%d unknown command %d\n",
proc->pid, thread->pid, cmd);
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
接着就会进入循环,开始读数据:
for (;;) {
//结合上面 bwr 的赋值,这里是要读数据
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
//向驱动发起读操作
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
//省略后续代码......
}
//ioctl 最终会调用到驱动中的 binder_ioctl
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
//......
switch (cmd) {
//......
case BINDER_WRITE_READ: //代码走这里
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
//......
}
}
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
//......
if (bwr.read_size > 0) {
//开始读数据
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
//......
}
//拷贝给用户空间
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
int ret = 0;
int wait_for_proc_work;
if (*consumed == 0) {
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
}
retry:
binder_inner_proc_lock(proc);
//使用 proc->todo 而不是 thread->todo
//这里会返回 true
wait_for_proc_work = binder_available_for_proc_work_ilocked(thread);
binder_inner_proc_unlock(proc);
//配置 looper 的值
thread->looper |= BINDER_LOOPER_STATE_WAITING;
if (wait_for_proc_work) {
//不会进入 if
if (!(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED))) {
binder_user_error("%d:%d ERROR: Thread waiting for process work before calling BC_REGISTER_LOOPER or BC_ENTER_LOOPER (state %x)\n",
proc->pid, thread->pid, thread->looper);
wait_event_interruptible(binder_user_error_wait,
binder_stop_on_user_error < 2);
}
binder_restore_priority(current, proc->default_priority);
}
if (non_block) {
if (!binder_has_work(thread, wait_for_proc_work))
ret = -EAGAIN;
} else { //代码走这里,等待binder工作到来,当有远程访问时,会从这里唤醒
ret = binder_wait_for_work(thread, wait_for_proc_work);
}
//......
}
static int binder_wait_for_work(struct binder_thread *thread,
bool do_proc_work)
{
//定义一个等待队列项
DEFINE_WAIT(wait);
struct binder_proc *proc = thread->proc;
int ret = 0;
freezer_do_not_count();
binder_inner_proc_lock(proc);
for (;;) {
//准备睡眠等待
prepare_to_wait(&thread->wait, &wait, TASK_INTERRUPTIBLE);
if (binder_has_work_ilocked(thread, do_proc_work))
break;
if (do_proc_work)
list_add(&thread->waiting_thread_node,
&proc->waiting_threads);
binder_inner_proc_unlock(proc);
//发起进程调度,进程进入休眠
schedule();
binder_inner_proc_lock(proc);
list_del_init(&thread->waiting_thread_node);
if (signal_pending(current)) {
ret = -ERESTARTSYS;
break;
}
}
finish_wait(&thread->wait, &wait);
binder_inner_proc_unlock(proc);
freezer_count();
return ret;
}
void prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state)
void wake_up_interruptible (wait_queue_head_t *q);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
这里涉及了 Linux 内核中进程调度相关的 API,这里简单介绍一下:
DEFINE_WAIT
这是一个宏,它定义了一个 wait_queue_t 结构体
#define DEFINE_WAIT_FUNC(name, function) \
wait_queue_t name = { \
.private = current, \
.func = function, \
.task_list = LIST_HEAD_INIT((name).task_list), \
}
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
2
3
4
5
6
7
8
这个结构体中的private域指向的即是当前执行系统调用所在进程的描述结构体,func域指向唤醒这个队列项进程所执行的函数
prepare_to_wait
这个函数将我们刚刚定义的wait队列项加入到一个等待队列中(在binder中即是加入到thread->wait中),然后将进程的状态设置为我们指定的状态,在这里为 TASK_INTERRUPTIBLE(可中断的睡眠状态,处于这个状态的进程因为等待某某事件的发生,比如等待socket连接、等待信号量,而被挂起。
schedule
schedule是真正执行进程调度的地方,由于之前进程状态已经被设置成TASK_INTERRUPTIBLE状态,在调用schedule后,该进程就会让出CPU,不再调度运行,直到该进程恢复TASK_RUNNING状态
wake_up_interruptible 这个函数会唤醒TASK_INTERRUPTIBLE状态下的进程,它会循环遍历等待队列中的每个元素,分别执行其唤醒函数,也就对应着我们DEFINE_WAIT定义出来的结构体中的func域,即autoremove_wake_function,它最终会调用try_to_wake_up函数将进程置为TASK_RUNNING状态,这样后面的进程调度便会调度到该进程,从而唤醒该进程继续执行
signal_pending 这个函数是用来检查当前系统调用进程是否有信号需要处理的,当一个进程陷入系统调用并处于等待状态时,如果此时产生了一个信号,仅仅是在该进程的thread_info中标识了一下,所以我们唤醒进程后需要检查一下是否有信号需要处理,如果有的话,返回-ERESTARTSYS,先处理信号,后续Linux上层库函数会根据-ERESTARTSYS此返回值重新执行这个系统调用
finish_wait 最后一步,当进程被唤醒后,调用finish_wait函数执行清理工作,将当前进程置为TASK_RUNNING状态,并把当前wait队列项从等待队列中移除